En esta práctica veremos como usar recon-ng para realizar un footprinting de un objetivo.
Al iniciar recon-ng nos encontramos con un framework vacío. Lo primero que debemos hacer es instalar modulos que habilitan diferentes tipos de funcionalidades en recon-ng (podemos pensarlos como extensiones o plugins).
Para ver los comandos disponibles usamos el comando help:
Usando Módulos
Con cualquier framework donde se utilicen módulos o extensiones es debemos conocer cuales comandos tenemos disponibles para poder buscar, instalar y eliminar los módulos cuando ya no los necesitemos.
Buscando Módulos en el Marketplace
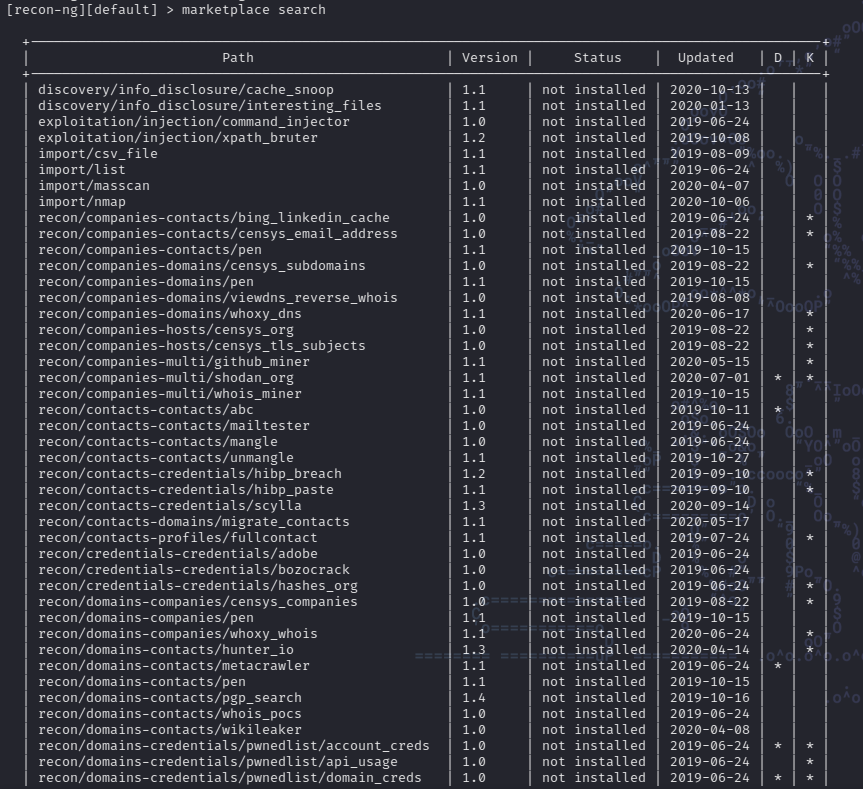
Para buscar que módulos disponibles existen para recon-ng, contamos con el comando marketplace search, con el cual recon-ng mostrara una lista de los módulos disponibles para ser instalados:
La lista de módulos disponibles es bastante extensa, y vemos que entre los detalles tenemos path, version, status, updated.
Adicionalmente tenemos dos columnas llamadas D y K que nos indican si el modulo tiene Dependencias(D) o si necesita de una key(K), como es por ejemplo el caso de shodan_ip.
Agregando API keys
Si el modulo que intentamos usar requiere una api key, podemos agregarla a recon-ng de la siguiente manera: keys add shodan_api {API_KEY}:
Las keys añadidas son almacenadas en el archivo keys.db en la carpeta donde se encuentra instalado recon-ng.
Instalando Módulos
Para poder instalar los módulos, contamos con el comando marketplace. Para instalar un modulo, por ejemplo shodan_ip. Usamos el siguiente comando: marketplace install shodan_ip:
De esta manera dejamos instalado el modulo seleccionado.
Cargando y configurando Módulos
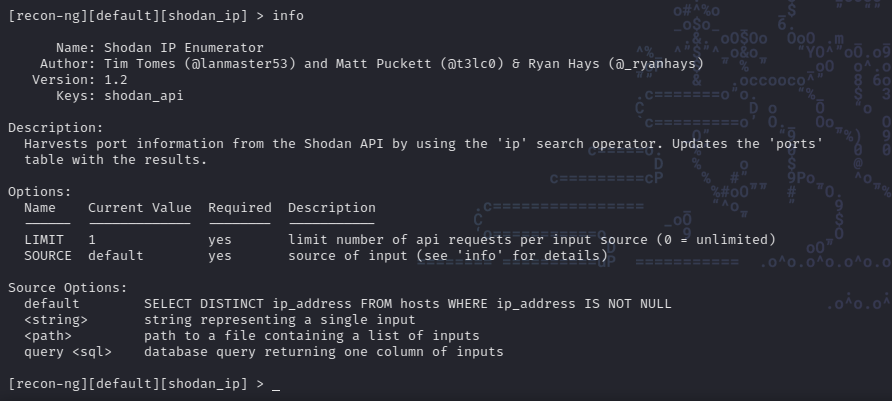
Es necesario cargar el modulo que se desea utilizar, en este caso: modules load shodan_ip. Similar a otros frameworks como metasploit. En recon-ng los módulos tienen diferentes opciones que debemos setear para poder ejecutarlos. Para ver las opciones requeridas (y opcionales) del modulo seleccionado usamos el siguiente comando: options list:
Si ejecutamos el comando info, podemos ver los distintos tipos de opciones que se pueden setear y sus valores actuales. Adicionalmente obtenemos un detalle de que valores podemos setear para la opción SOURCE.
Seteando Opciones
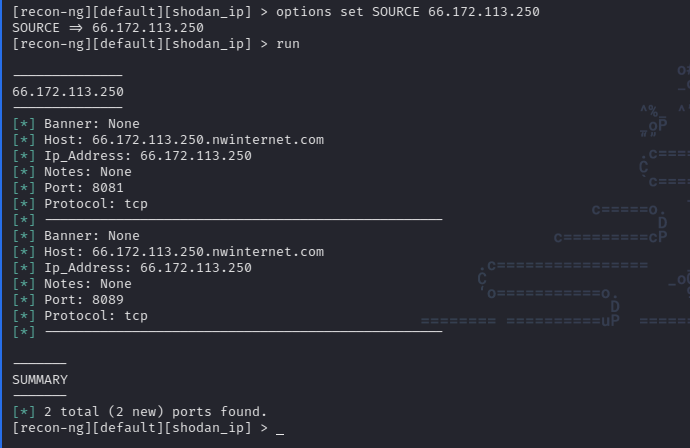
Para setear las opciones usamos el comando options set {NOMBRE_OPCION}, en este caso el modulo necesita que SOURCE este seteado. El source en nuestro caso es el IP del objetivo (obtenido en shodan.io):
Ejecutando el Módulo
En este punto ya estamos listo para ejecutar el modulo, para eso usamos el comando run:
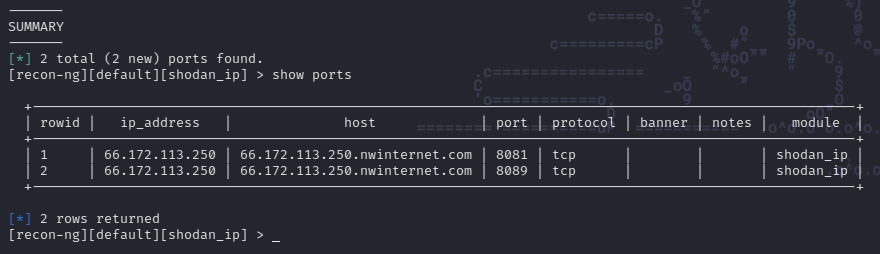
Como podemos ver el modulo realiza un escaneo del objetivo y nos devuelve ciertos detalles sobre el mismo. Si ingresamos el comando show ports podemos ver la lista de puertos descubiertos durante el scan:
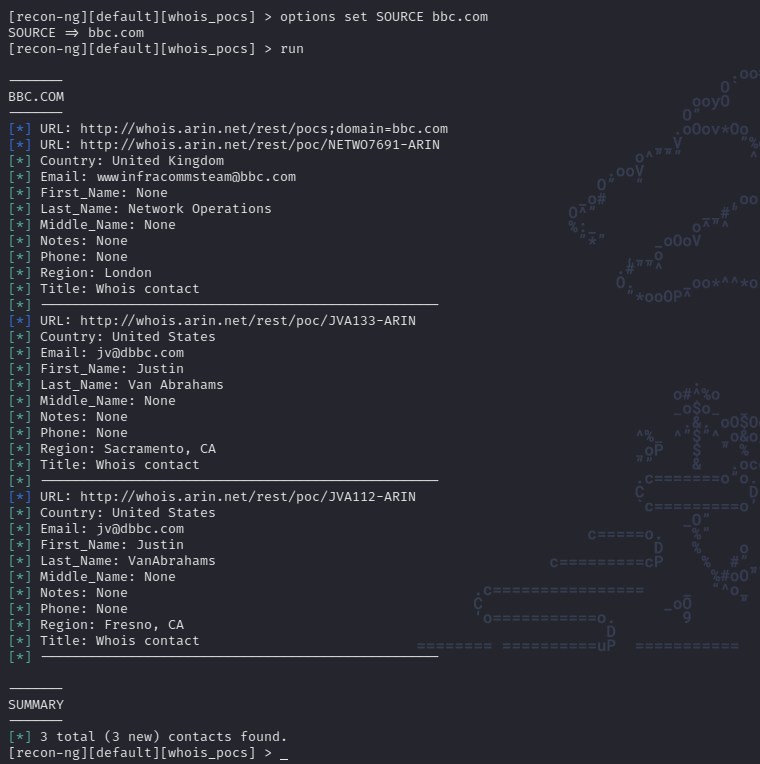
También es posible usar otros módulos que devuelven otro tipo de información. Por ejemplo podemos instalar el modulo whois_pocs, configurarlo y ejecutarlo:
De esta manera realizamos un scan simple utilizando shodan para obtener puertos abiertos y luego usando el modulo whois_opcs obtuvimos información de whois en un scan adicional.
Workspaces en Recon-ng
Es importante tener en cuenta que recon-ng nos permite organizar nuestra información en diferentes workspaces o espacios de trabajo. La ventaja de esto es que podemos tener nuestra información separada por ejemplo, por objetivos o clientes para los cuales estemos haciendo reconocimiento. De esta manera es muy simple tener un espacio por ejemplo para todo lo relacionados a nuestras tareas de reconocimiento de microsoft.com y en otro workspace tener todo lo relacionado a udemy.com.
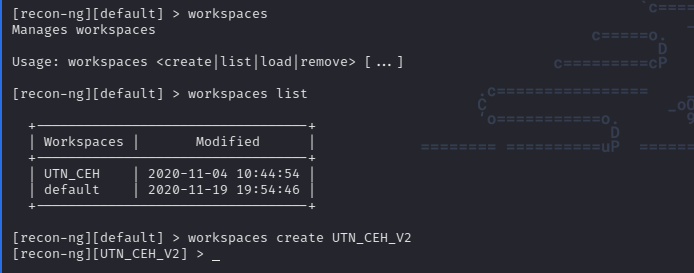
El uso de workspaces es muy simple como vemos a continuación:
workspaces list nos deja ver todos los workspaces existentes.
workspaces create {NOMBRE_WORKSPACE} nos permite crear uno nuevo.
workspaces load {NOMBRE_WORKSPACE}
Running scans with Nmap
Distintos ejemplos de como correr variados tipos de scans usando Nmap.
Intro: Distintos tipos de scans con Nmap
En esta práctica veremos como usar nmap para realizar distintos tipos de escaneos mediante los cuales obtendremos distintos detalles de nuestro objetivo. Para esta práctica voy a usar un laboratorio local que tengo creado para practicas de Active Directory como objetivo. Este lab corre en VMware localmente y consta de los siguientes equipos:
Ethical Hacking Notes
⛔ Todo el contenido demostrado en este compendio de escritos, es exclusivamente para el estudio de hacking ético.
Bienvenido a mis notas de estudio del curso de CEH de la UTN y de hacking ético en general, espero que te resulten de utilidad para tus estudios y prácticas. Cada uno de estos escritos nace en principio como una práctica a un modulo de la cursada, pero no solo queda en la mera práctica. Trato de de cada escrito tenga el suficiente detalle e ilustre el uso básico de cada herramienta o proceso y no solo sea un mini documento donde se resuelve lo pedido y ya.
La idea de estos escritos es realmente generar documentación que sirva a futuro como referencia o guía rápida para cuando necesite consultarlos nuevamente. Y que puedan ser compartidos libremente con la comunidad de estudiantes que necesiten acceso a información de consulta para sus estudios.
Creando un diagrama de red con Network Topology Mapper
Para esta práctica veremos como realizar un diagrama de una red, utilizando NTM para realizar un scan de topología de red.
Solarwinds Network Topology Mapper
Para esta práctica veremos como realizar un diagrama de una red, utilizando NTM para realizar un scan de topología de red.
nos permite cargar y marcar como activo un determinado workspace.
workspaces remove {NOMBRE_WORKSPACE} nos permite borrar un workspace.
Tipo
IP
DC: Controlador de Dominio
192.168.31.131
Client1: Win 10 Enterprise
192.168.31.132
Client2: Windows 10 Pro
192.168.31.133
Este lab esta destinado a practicar ciertas vulnerabilidades de varios tipos, algunos de ellos detallados a continuación:
LLMNR and NBT-NS Poisoning
SMB Relay Attacks
Kerberoasting
Golden Ticket
Token Impersonation
IPv6 DNS Takeover Attacks
Esta práctica no cubre las vulnerabilidades mencionadas ni la creación del lab, únicamente lo usaremos como objetivo para aprender los distintos tipos de escaneos.
Teniendo esto en cuenta debería servirnos para obtener información mediante los distintos tipos de scan usando Nmap que veremos en esta práctica.
Nmap es una herramienta que consta de muchas formas de uso, no es el objetivo de esta práctica cubrir todas. Simplemente veremos algunos tipos de escaneos a modo de ejemplo, principalmente los que uso comúnmente para resolver labs como los de VulnHub y TryHackMe entre otros.
Parte 1: Escaneos Básicos.
En esta primer parte del práctico veremos los escaneos más simples que podemos realizar con nmap.
Haciendo ping con Nmap.
Lo primero que podemos probar es como hacer ping a nuestro objetivo. Por el momento comencemos por un solo IP objetivo, el del controlador de dominio.
Para hacer un simple scan de un host con nmap podemos hacer uso del siguiente switch -sn, el mismo nos devuelve varios detalles del objetivo aparte de informarnos si el host esta activo, como ser la latencia y la dirección MAC del host.
-sn: Ping Scan - disable port scan
El comando completo queda de la siguiente manera:
nmap -sn 192.168.31.131
El uso de sudo no es necesario para este scan.
Con este simple scan obtuvimos la siguiente información de nuestro objetivo:
Info Obtenida
Valor
Estado del Host (Activo/Inactivo)
Host is up
MAC Address
00:0C:29:1C:F8:3D (VMware)
Latencia
0.00039s
Detectando el Sistema Operativo.
Para detectar el sistema operativo del objetivo podemos usar el siguiente switch de nmap: -O. Lo que nos devuelve el siguiente output en la consola:
El comando completo nos queda de esta forma:
sudo nmap -O 192.168.31.131
Este switch requiere ser ejecutado con privilegios.
Como vemos este scan no solo intenta detectar el SO (OS fingerprinting), sino que también ejecuta algunos análisis adicionales como ser detección de puertos comunes y detección de servicios corriendo en cada puerto.
En este caso vemos que no fue posible detectar el SO correctamente, posiblemente por alguno de los ajustes que tengo realizados en el laboratorio local. Es importante saber que disponemos de un switch alternativo para intentar detectar el SO más agresivamente: --osscan-guess .
Veamos como es el output cuando logra detectarlo correctamente:
También vemos que incluye los datos que vimos en el scan anterior.
Info Obtenida
Valor
Listado de puertos abiertos y sus servicios
PORT STATE SERVICE
53/tcp open domain
88/tcp open kerberos-sec
135/tcp open msrpc
139/tcp open netbios-ssn
389/tcp open ldap
445/tcp open microsoft-ds
464/tcp open kpasswd5
Distancia de red hasta el host
1 hop
Posible Versión del Sistema Operativo (Host de ejemplo)
Windows XP SP3 o Windows Server 2012
Escaneando puertos específicos.
Para escanear determinados puertos podemos hacer uso del switch -p el cual nos permite especificar una serie de puertos específicos, sobre los cuales realizar un scan.
El comando queda de esta manera:
nmap -p 53,88,389,445 192.168.31.134
De esta manera podemos escanear los puertos deseados.
Si queremos escanear por un rango de puertos en particular podemos hacerlo de la siguiente forma:
nmap -p 54-445 192.168.31.131
Escaneando todos los puertos (65535).
Si en cambio queremos escanear todos los puertos podemos hacerlo de la siguiente manera, usando el switch -p-.
El comando queda de esta forma:
nmap -p- 192.168.31.131
Para este host en particular use el switch -Pn que nos permite indicarle a nmap que no realice pings. Necesario para objetivos que no responden a ping (ICMP) echo requests.
Escaneo de Versiones.
Para realizar un escaneo que nos ayude a identificar las versiones de los servicios que están corriendo en el objetivo podemos hacer uso del siguiente switch -sV.
El comando queda de esta forma:
nmap -sV 192.168.31.131
TCP/IP Full Open Scan
Si queremos realizar un escaneo completamente abierto, podemos hacer uso del switch -sT. En este tipo de escaneo generalmente nos asegura una respuesta dado que la sesión se inicia en su totalidad (SYN, SYN+ACK, ACK, RST).
Importante: Este escaneo es fácilmente detectado por firewalls y otras medidas de seguridad.
Para realizar este scan el comando queda de la siguiente manera:
nmap -sT 192.168.31.131
Stealth Scan (Half-open)
En muchos casos necesitamos realizar escaneos sin alertar o disparar detecciones del lado del objetivo. Para estos casos nmap cuenta con el switch -sS. En este tipo de scan la sesión no se completa correctamente, y únicamente los paquetes SYC, SYNC+ACK y RST son utilizados. Cuando el objetivo responde, el cliente en vez de responder con ACK responde directamente con RST.
Este comando requiere de privilegios para correr (sudo).
Para ejecutar este tipo de scan el comando queda de la siguiente forma:
nmap -sS 192.168.31.131
Como explique antes el switch adicional -Pn es necesario para hosts que no responden a ping requests (ICMP Echo Requests) como es el caso de este objetivo que estoy usando.
Escanear equipos en la red
Si queremos obtener un panorama general de los equipos que están activos en la red que estamos escaneando podemos hacer uso del switch -sP. El mismo puede llevar un tiempo terminar dependiendo que tan extensa sea nuestra red. En Este caso el lab objetivo es bastante pequeño.
Podemos usar el comando de esta manera:
nmap -sP 192.168.31.*
Notemos que en este caso estamos pasando parte del IP, e indicamos el último valor como * para que nmap automáticamente escanee todos los equipos que formen parte del mismo subnet.
Alternativamente podemos hacer uso de los switches-PS (SYN Ping) o -PR (ARP Scan) los cuales nos regresan resultados como estos:
De momento no explicaremos el uso de los switches/flags adicionales que puedes ver en la imagen anterior. Cubriremos esos más adelante en esta práctica.
Escaneo con Default scripts
Nmap incorpora scripts (NSE) que nos permiten indicar si durante el escaneo queremos que nmap también intente correr los scripts con los que viene incorporados. Estos scripts prueban vulnerabilidades comunes que pueden aportar buena información sobre el objetivo y sobre como lograr explotarlos para obtener acceso. Esto se realiza mediante el switch -sC.
El comando para este tipo de scan es el siguiente:
nmap -sC 192.168.31.131
Vemos que los resultados que obtenemos incluyen mucha información sobre el controlador de dominio (en este caso) escaneado. Estos resultados varían dependiendo de que objetivo estemos escaneando y cuales sean las vulnerabilidades que nmap pueda detectar para cada caso en particular.
Parte 2: Escaneos múltiples.
En esta parte del práctico veremos algunos escaneos más avanzados y comenzaremos a usar varios switches o flags al mismo tiempo en nuestros comandos.
Digamos que quiero obtener rápidamente toda la información que vimos, en los escaneos individuales, para tener un panorama general del objetivo lo más pronto posible. Normalmente cuando ejecuto un scan con nmap para algún laboratorio comienzo teniendo en cuenta lo siguiente:
Tipos de datos que necesito obtener
Tipos de datos que me gustaría obtener
Que tan rápido quiero obtener los resultados
Usualmente en los labs de práctica o challenges del tipo Capture The Flag (Captura la bandera), utilizo el siguiente set de switches o flags de nmap:
Como podemos ver en esa línea anterior, hay varios switches o flags nuevos que estamos pasando a nmap que no hemos visto en esta práctica aún. Veamos uno a uno que función cumplen.
Switch/Flag
Función
-T5
Indica la velocidad del scan. Valores posibles 1 a 5, siendo 5 el más alto. (Aumenta la detención de nuestro scan por parte de los mecanismos de defensa que tenga el objetivo)
-v
Indica a nmap que debe producir output verboso, proveyendo al usuario con mucho detalle sobre cada scan y su resultado.
-oN <archivoSalida>
Indica a nmap que debe generar un archivo de salida con los resultados. En este caso en formato común (texto).
Este tipo de escaneo suele resultar en un output extenso en la consola, por eso es buena idea guardarlo directamente a un archivo para consultarlo cuando sea necesario.
El resultado de este scan en su totalidad de puede ver en el siguiente bloque, dado que no amerita capturarlo en imágenes en su totalidad:
De esta forma vimos variados tipos de escaneos que podemos realizar con nmap para obtener importante información sobre nuestro objetivo. En la siguiente sección recopilaremos rápidamente todos los datos que logramos obtener a lo largo de esta práctica sobre el objetivo escaneado.
Parte 3: Recopilando la información.
En esta parte recopilaremos y presentaremos toda la información que obtuvimos de todos los tipos de escaneos practicados.
Durante esta práctica vimos de que manera podemos utilizar un subset de funcionalidades ofrecidas por nmap para realizar distintos tipos de escaneos a nuestro objetivo con el fin de obtener una serie de detalles para nuestro pentest.
Dato
Detalle
Puertos abiertos y servicios (DC)
53 (domain Simple DNS Plus)
135 (MS Windows RPC)
139 (MS Netbios SSN)
445 (MS DS)
49703 (MS Win RPC)
9389 (.NET Message Framing)
49667 ( MS Win RPC)
3268 (MS Active Directory LDAP)
Hasta acá llegamos con esta práctica de scanning con nmap, vimos como ejecutar distintos tipos de scan para obtener variadas piezas de información y aprendimos el usó básico de nmap.
Estas prácticas están sujetas a modificaciones y correcciones, la versión más actualizada disponible se encuentra online en el siguiente link.
Estos escritos detallan mis apuntes y notas personales creadas para comprender y practicar los contenidos de la cursada y algunos adicionales. Los mismos estarán en constante revisión y actualización. Todos están creados por mi para estudio y futura consulta y pueden contener errores propios de quien esta en constante aprendizaje. Si ves algo que se pueda mejorar no dudes en mencionarlo, puedes comunicarte conmigo en Twitter @tzero86 en cualquier momento.
También están disponibles guías técnicas sobre resolución de laboratorios en mi blog (solo en Ingles por el momento).
Beware of the dog, you have been warned. 😎
Non-Profit | Open Source | Freely and Publicly Available content
Todo el contenido esta ofrecido gratuitamente y sin fines de lucro, libre de uso para cualquier estudiante interesado. En este espacio creemos en compartir el conocimiento y hacerlo accesible a todo estudiante, especialmente a aquellos estudiantes de países en desarrollo donde el costo de vida y las restricciones económicas hacen muy difícil el acceso a documentación y recursos pagos para el estudio. 💚
Si estos escritos te sirven para tus estudios, eres bienvenido a copiarlos para tu futura referencia. Agradezco en ese caso si me dejan un comentario en Twitter haciéndome saber que te fueron útiles (lo cual me motiva a seguir creando contenido) o bien dejar la mención a este compilado de apuntes donde quiera que uses mis textos.
Saludos,
👽
Esta obra está bajo una .
Conociendo NTP
SolarWinds NTM nos permite realizar un scaneo mediante el cual podemos descubrir los elementos que componen una red objetivo y según los IPs que usemos, automáticamente generar un diagrama de dicha red.
Al iniciar NTM vemos una suerte de wizard donde podemos iniciar nuestro primer scan. El wizard nos ofrece diversas opciones para configurar: Proveer credenciales, rangos de IP, Dominios, direcciones IPV6, etc.
En nuestro caso queremos realizar un scan básico por ende en el paso de Network Selection definiré una serie de IPs obtenidas mediante Shodan.io. Dichas IPs pertenecen a la Universidad de Ljubljana en Lituania.
Si avanzamos por el wizard tendremos la posibilidad de definir un nombre para nuestro scan, debajo de esa opción vemos también una opción para ignorar los nodos de red que no únicamente respondan a ping (ICMP) y no a SNMP/WMI:
Si presionamos next llegamos a la parte de scheduling donde podremos configurar nuestro scan para ejecutarse inmediatamente o bajo cierta frecuencia que podemos definir manualmente.
En este caso ejecutaremos el scan inmediatamente:
Al darle next veremos que la ultima etapa del wizard es un resumen de todos los seteos que configuramos en los distintos pasos. Vemos también un botón llamado discovery que nos permite iniciar finalmente el proceso de scaneo:
Una vez que el scan comienza vemos que abre una nueva ventana con el progreso actual del mismo:
Una vez que el scan termina, podemos ver listados en el panel de la izquierda los nodos que fueron detectados:
Estos nodos podemos usarlos para ir construyendo nuestro diagrama, basta con arrastrarlos al mapa en blanco y serán agregados:
Como podemos ver el scaneo de las IPs que definimos realmente no sirvieron para generarnos un diagrama automáticamente.
Definiendo un Objetivo para obtener un diagrama automático de red
Veamos si logramos encontrar algún IP objetivo que nos permita ver como NTM genera automáticamente un diagrama de los nodos de red luego de realizar el scaneo del objetivo. Para esto usaremos como ejemplo nuestra red local:
Como podemos observar esta vez obtenemos 8 nodos de red y una subnet como resultado de nuestro scan. Si arrastramos los nodos al mapa vemos que esta vez si se generan las líneas de conexión. De cada nodo podemos obtener su dirección IP, lo cual nos permitirá a futuro usar otras herramientas y obtener información adicional de cada nodo.
NTM nos ofrece distintas formas de organizar nuestro mapa de red usando las opciones listadas debajo de la lista de nodos en la sección llamada Map Layouts. También podemos realizar distintas acciones sobre cada nodo. Para esto podemos hacer click derecho sobre cualquier nodo y veremos las opciones disponibles:
En este caso vemos que podemos realizar conexiones de escritorio remoto, TraceRoute, Ping y Telnet.
Recolectando los resultados
Por medio de esta práctica obtuvimos los siguientes datos:
La Subnet 192.168.1.0/24 contiene los siguientes nodos de red de los cuales obtuvimos las siguientes direcciones IP:
192.168.1.34
192.168.1.34
192.168.1.35
192.168.1.38
192.168.1.41
192.168.1.43
192.168.1.46
Esta recolección de información nos permite tener una idea más detallada de la red objetivo y la obtención de los IPs nos permitirá realizar distintos tipos de scaneos a futuro usando, por ejemplo, nmap para identificar puertos abiertos y servicios en ejecución.
Fingerprinting with FOCA
En esta práctica veremos como hacer fingerprinting de archivos usando FOCA.
En esta oportunidad vamos a hacer un scan con la herramienta llamada FOCA(Fingerprinting Organizations with Collected Archives).
Para esta práctica voy a usar www.globant.com como objetivo inicial para conocer un poco sobre FOCA y su uso. Luego usaremos algún otro objetivo para ver casos donde haya metadata expuesta.
Uso básico de FOCA
Como primer paso configuramos el proyecto y el dominio objetivo:
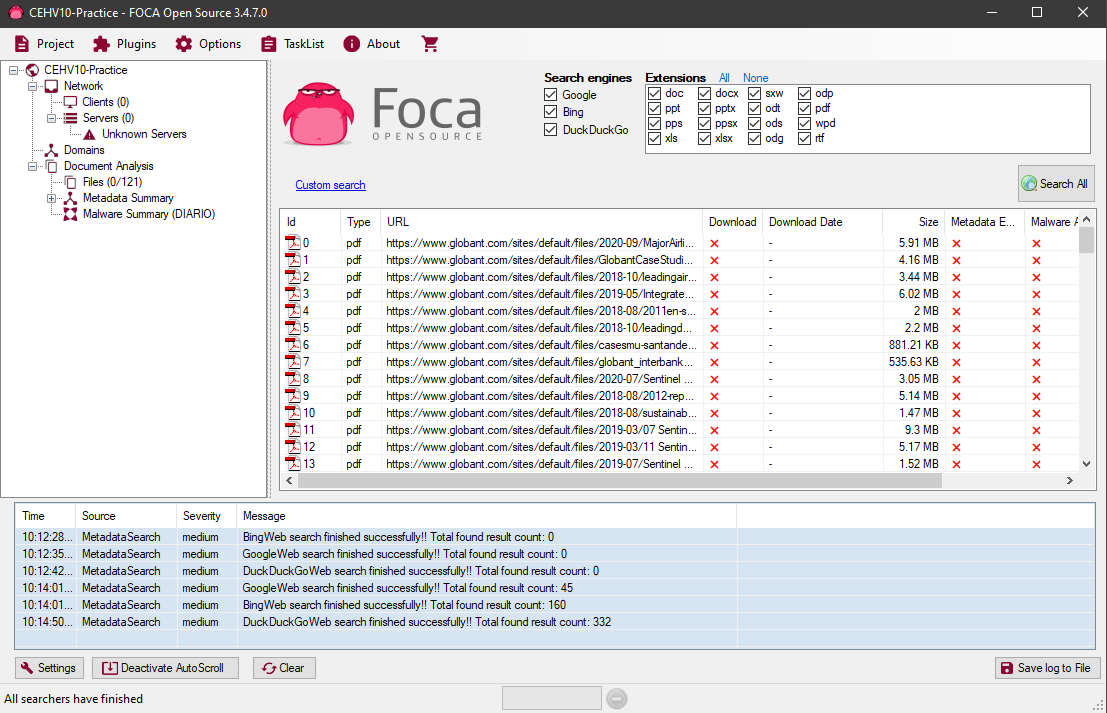
Una vez listo, seleccionamos las extensiones de archivo que queremos que sean tomadas en cuenta por FOCA al realizar el scan:
Una vez listo, hacemos click en Search All para iniciar el scan. Una vez que FOCA comienza a detectar archivos los vemos listados debajo de la selección de extensiones de archivos:
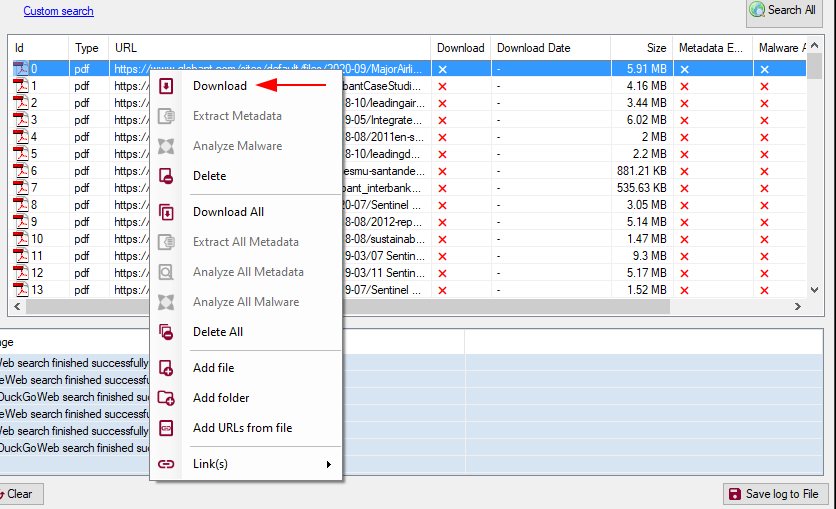
Una vez tenemos resultados disponibles, podemos hacer click derecho sobre cualquiera de los archivos listados y darle click en Download para descargarlo y ver que información podemos obtener del mismo:
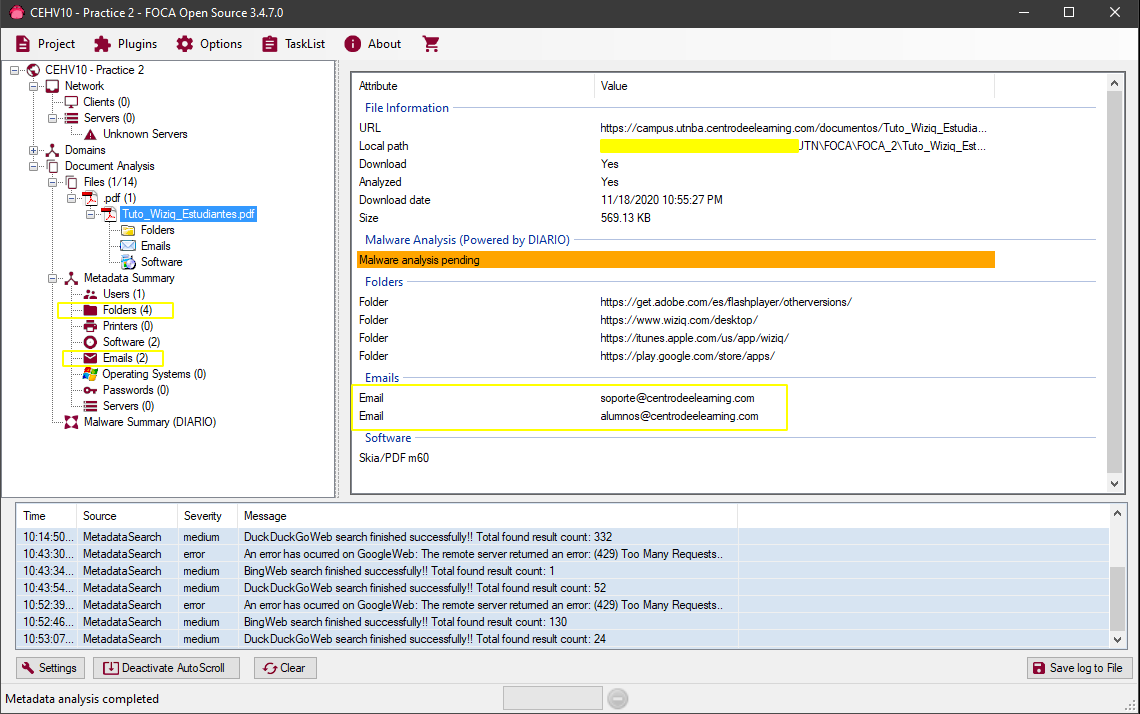
Una vez descargado el documento aparece listado en el tree view y podemos observar algunos detalles del mismo.
Para ver los detalles de la metadata del archivo necesitamos volver a la lista de archivos y luego darle click derecho al archivo deseado y click en Extract All metadata y luego Analyze all metadata.
En este caso no obtenemos información importante dado que estos documentos ya fueron sanitizados antes de ser publicados. Pero en caso de obtener algún detalle importante de la metadata de los mismos, FOCA listara los diferentes tipos de información en el tree view para que podamos revisarlos:
Análisis de Metadata Expuesta con FOCA
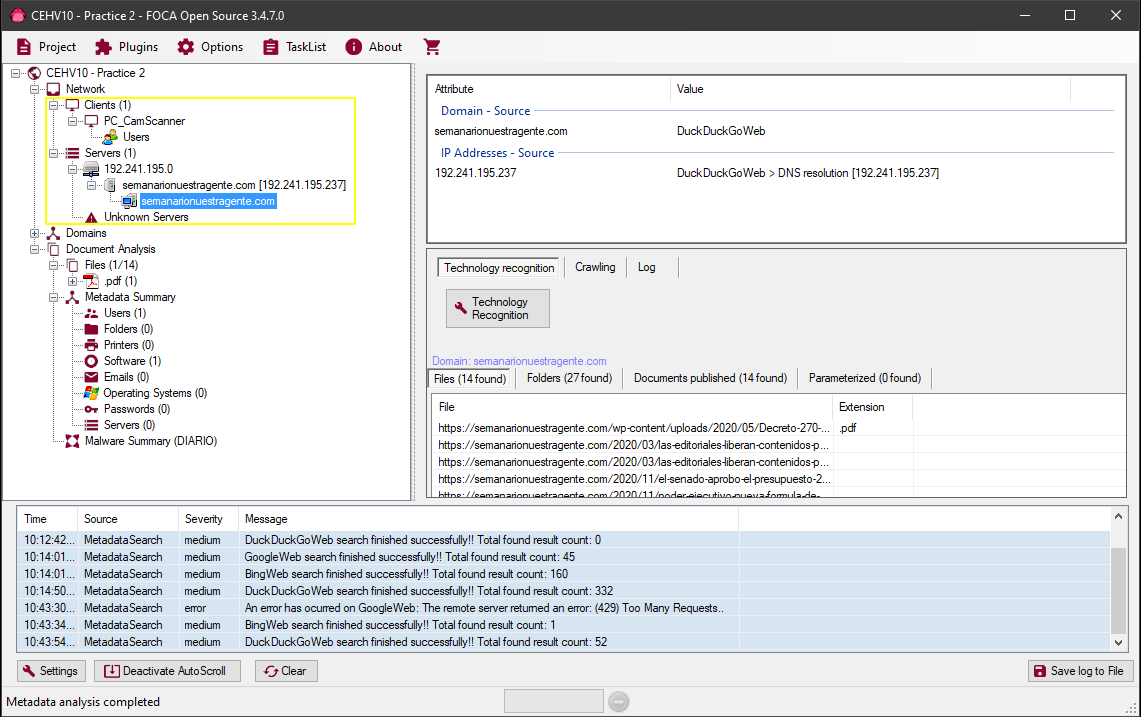
Si vemos un ejemplo de un archivo que si expone ciertos datos en su metadata veremos como esta información es presentada en FOCA:
Vemos que entre los resultados obtenemos:
La dirección IP del servidor
El Software usado para crear el Archivo
El User usado al crear el archivo
Cada archivo escaneado puede exponer distintas piezas de información que nos dejan obtener una imagen más completa del objetivo durante la etapa de reconocimiento.
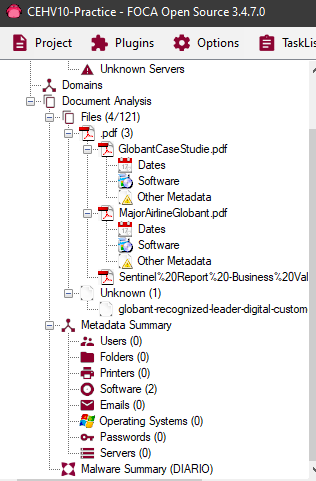
En este otro ejemplo vemos que un PDF del campus de la UTN revela diferentes detalles al analizarlo:
En este caso obtenemos algunas carpetas(Folders), algunos emails y la versión del software usado en la creación del documento.
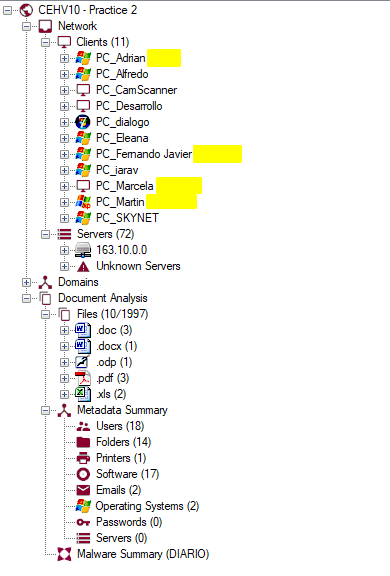
Algunos documentos revelan mucha más información:
En este caso podemos ver que la metadata extraída de ciertos documentos, exponen cuentas de usuarios, correos, impresoras, carpetas, incluso otros servidores. Claramente sanitizar los documentos antes de compartirlos es clave para prevenir que agentes externos puedan obtener detalles potencialmente sensibles con herramientas como FOCA.
Footprinting with Maltego
En esta práctica veremos como usar Maltego para realizar un footprinting.
En esta práctica usaremos Maltego en su versión gratuita (Community Edition) para entender como podemos, utilizando esta herramienta, llevar a cabo un footprinting de una web objetivo.
Instalando Transforms
En Maltego los "Módulos" se llaman Transforms cada uno de ellos aporta funcionalidades y diversos tipos de scans que podemos utilizar.
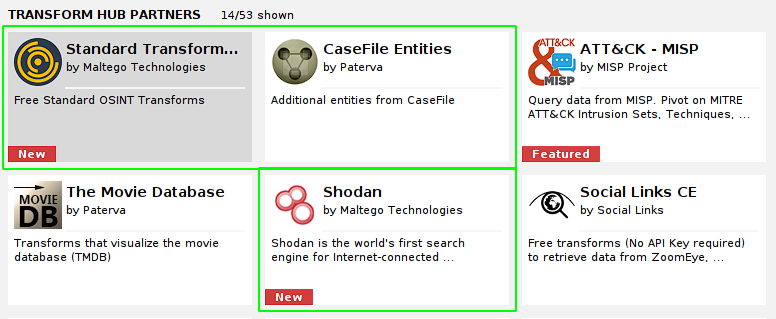
Para instalar transforms, Maltego dispone de una sección llamada transform hub:
El hub es una suerte de store o market donde podemos encontrartransforms pagos, gratuitos y algunos que ofrecen free trials (pruebas gratuitas). Disponemos de filtros para refinar nuestra búsqueda. En este caso en particular usaremos todos transforms gratuitos para hacer nuestra práctica de reconocimiento web.
En mi caso voy a utilizar los siguientes transforms gratuitos:
La instalación de los transforms es sencilla, basta con clickear cada una y elegir la opción install. Luego una ventana se abrirá para comenzar la instalación.
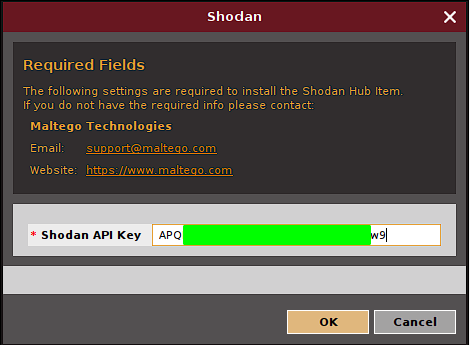
Algunos transforms como el de Shodan, requieren una API Key para funcionar y pedirán la misma durante la instalación:
Reconocimiento web con Maltego
El objetivo de esta práctica es generar un reconocimiento web usando Maltego y los transforms que instalamos previamente.
Creando un nuevo scan
Para iniciar generamos un nuevo graph desde el menú de Maltego:
Una vez creado vemos que disponemos de una suerte de canvas vacío donde vamos a poder organizar los elementos de nuestro scan. Estos elementes en Maltego se llaman Entities. Podemos ver una lista de cada una en el panel a la izquierda de nuestro canvas, diferenciados por categorías.
Definiendo el Dominio (Entities)
Las Entities nos permiten ubicar en el canvas los distintos tipos de dispositivos, eventos, infraestructuras, locations, Personal, etc.
Para comenzar nuestro scan, buscamos en la lista de entidades la entidad llamada Domain:
Para agregar nuestra entidad al canvas, basta con arrastrarla y soltarla sobre el mismo. Por default esta entidad apunta a paterva.com. Necesitamos ajustar ese valor y apuntarlo a nuestro objetivo. Para ello disponemos de 2 formas:
Opción 1: Hacer doble click en el texto de la entidad y cambiar el valor al dominio objetivo:
En mi caso utilizaré como objetivo una web de noticias online:
https://semanarionuestragente.com/
Realizando el primer scan Manual
En Maltego cada entity nos ofrece diversos tipos de scan (en realidad también son llamados transforms). Los mismos son habilitados por los transforms que tengamos instalados. Cada entidad puede contener distintos tipos de scans disponibles según su tipo. Para ver los scans disponibles, podemos hacer click derecho sobre la entidad:
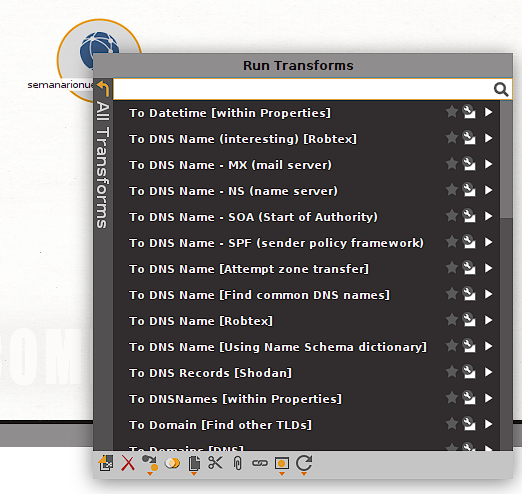
Vemos que el menú contextual que se despliega es llamado Run Transforms. El mismo nos presenta cada transform instalado, podemos hacer click sobre alguno en particular o bien hacer click en All Transforms para ver la lista completa de opciones disponibles:
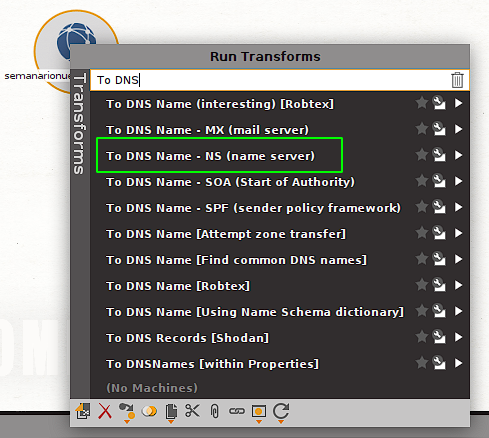
Comenzaremos por hacer un scan del tipo whois. Podemos usar la barra de búsqueda del menú contextual para refinar la lista y por ejemplo ver los scans de tipo whois que están disponibles:
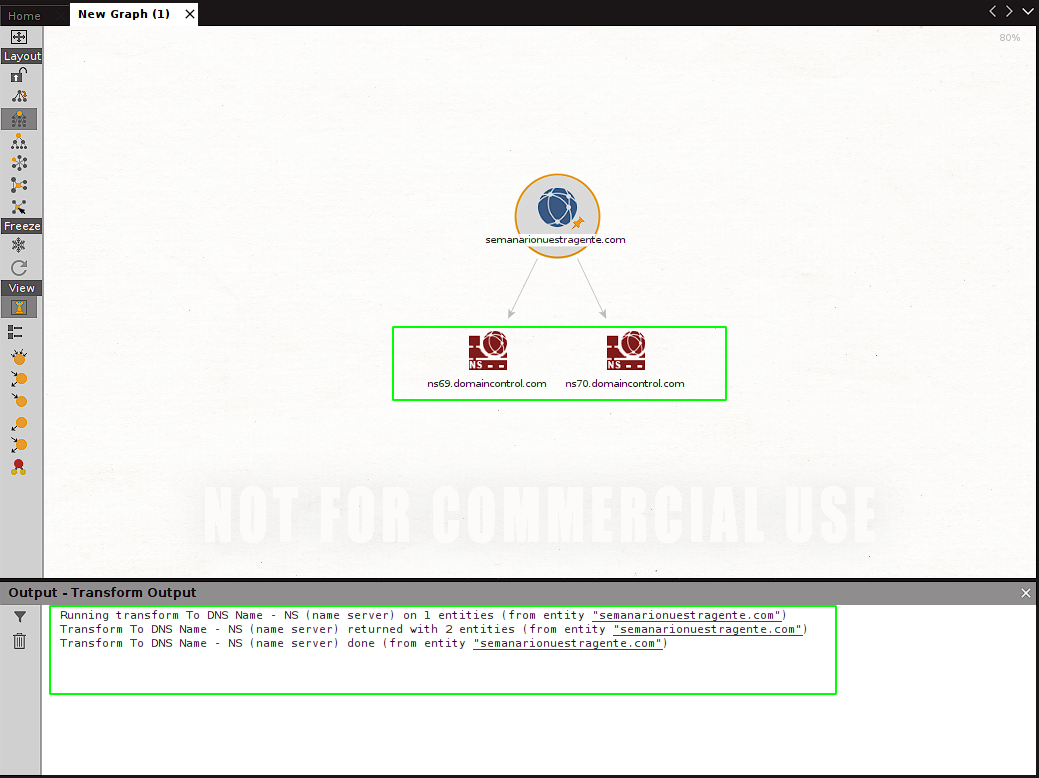
En este caso probaremos el transform (scan) llamado to DNS - NS (Name Server). Al hacerle click el scan/transform seleccionado es ejecutado. Vemos que luego de un momento 2 nuevas entidades aparecen en nuestro canvas. También podemos ver que cada transform/scan genera un log al ejecutarse que se muestra en la ventada de output debajo del canvas:
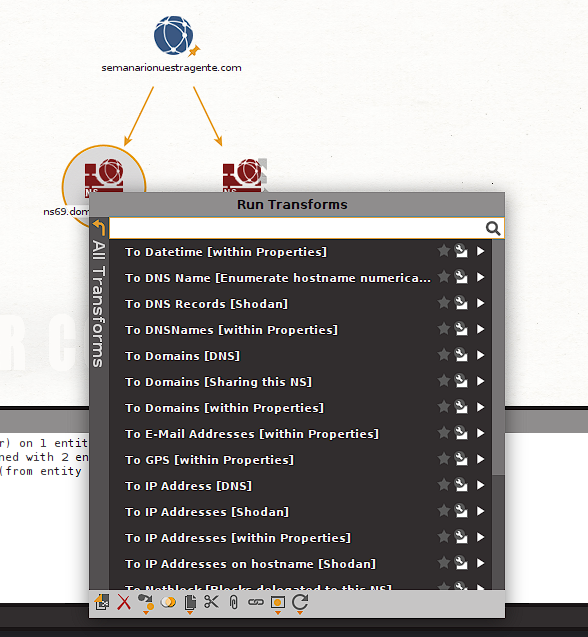
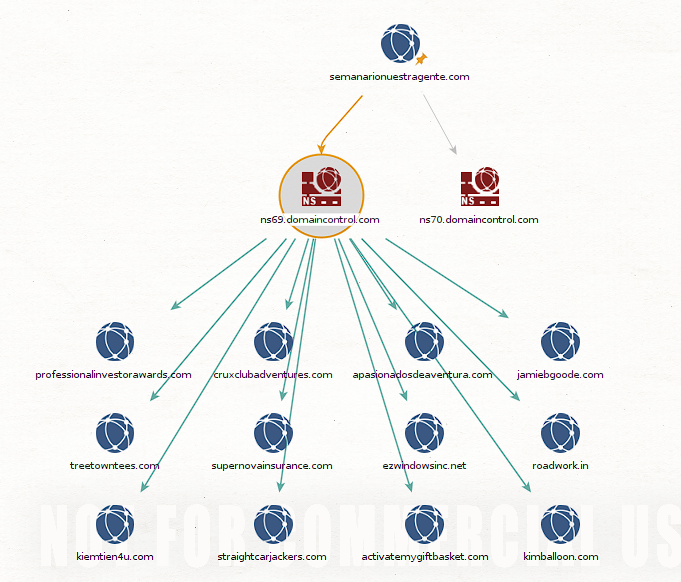
De esta manera vemos que obtenemos ambos Name Servers que están vinculados a nuestro objetivo. Estas nuevas entidades nos permiten correr scans adicionales. Veamos cuales están disponibles para ns69.domaincontrol.com:
Probemos correr el transform llamado To Domains [Sharing this NS] y al correr vemos que nos actualiza el canvas con todos los dominios que también utilizan ese mismo Name Server:
Ya nos podemos ir dando una idea del potencial de Maltego para hacer reconocimiento de nuestros objetivos.
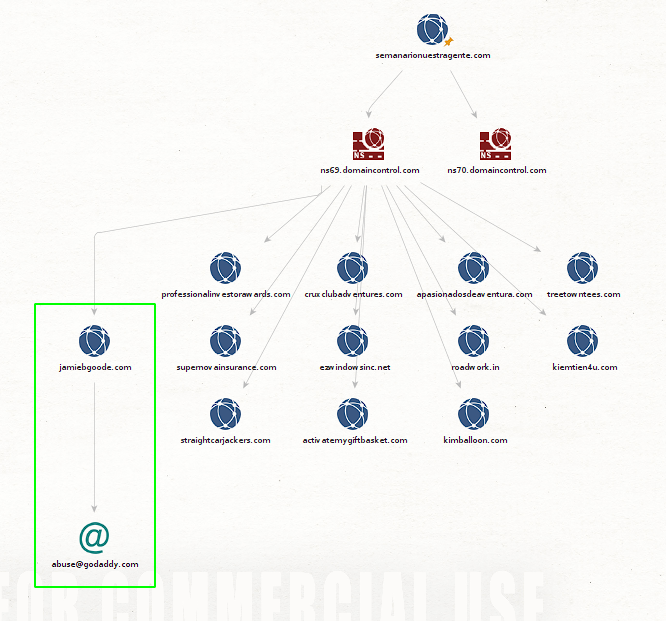
Tomemos para nuestro próximo scan a jamibgoode.com y corramos el transform llamado To Email Address [from whois info]:
Vemos que de esta manera logramos listar el correo que esta especificado en los registros de whois para ese dominio. De esta forma podemos comenzar a obtener información sobre nuestro objetivo, pero Maltego también nos ofrece otra forma automatizada de realizar escaneos de footprinting usando lo que se llama machines.
Usando Machines para Footprinting Automático
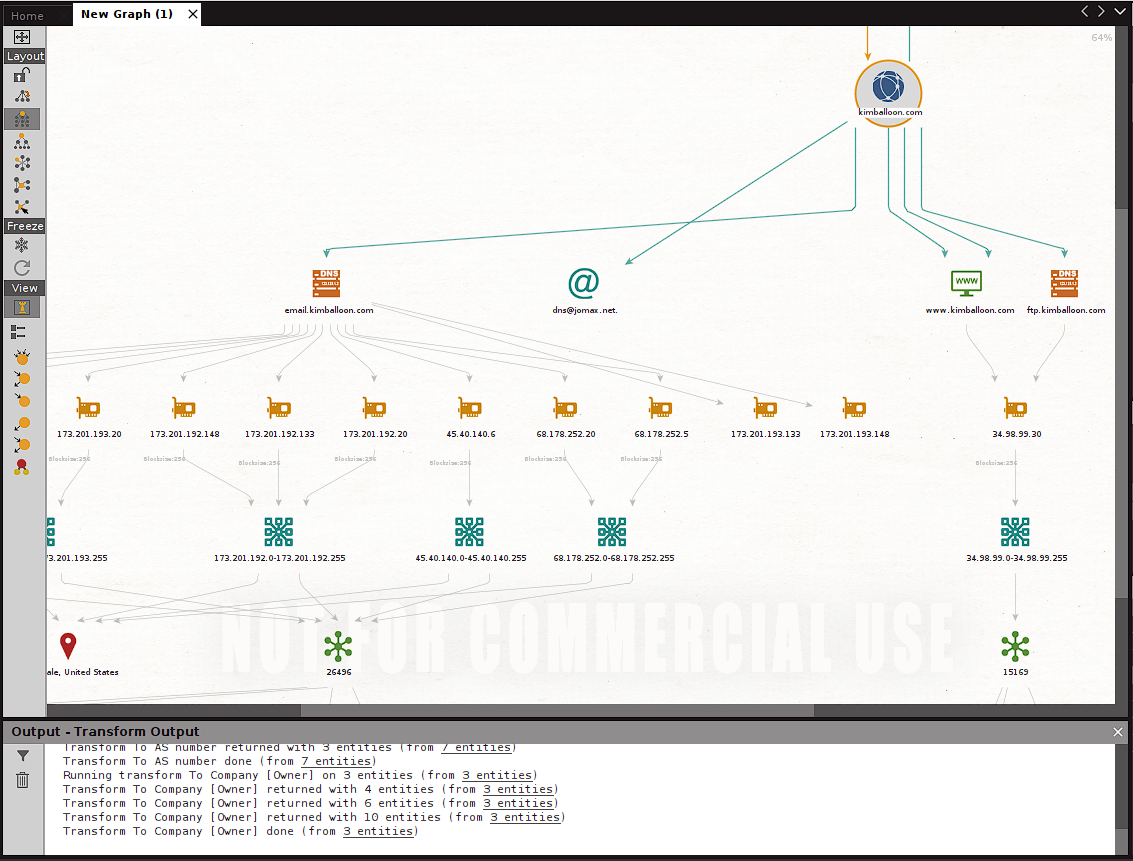
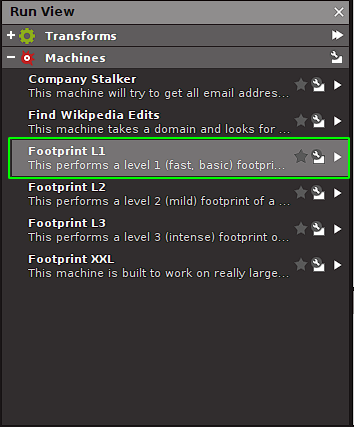
Maltego pone a nuestra disposición diferentes machines que son una suerte de scans pre-seteados que podemos ejecutar automáticamente para el dominio objetivo que hemos definido. Veamos como podemos usar machines para hacer footprinting, esta vez para el dominio kimballoon.com:
Primero ubicamos la machine que deseamos ejecutar, para esta práctica usaremos la llamada Footprint L1. Basta con hacer click en la machine deseada para ejecutarla:
En la versión community de Maltego esta limitada la funcionalidad y potencia de estas machines.
Luego de ejecutar la machine, en la parte superior derecha de la pantalla de Maltego vemos el resultado de los scans/transforms ejecutados por dicha machine. Y al ver el canvas vemos que tenemos múltiples nuevas entidades, cada una de las cuales nos sigue proveyendo de información adicional para nuestro esfuerzo de footprinting:
Vemos que en este caso el footprinting realizado nos genera en nuestro canvas una considerable cantidad de nuevas entidades de variados tipos. Cada una de las cuales nos permite seguir utilizando transforms adicionales para intentar conseguir información y detalles adicionales que luego podemos recopilar para tener un panorama lo más completo posible de nuestro objetivo.
Como podemos observar el poder de Maltego es considerable y la facilidad de uso que nos ofrece la convierte en una herramienta formidable para nuestros esfuerzos de footprinting y reconocimiento.
Durante esta simple práctica vimos algunas de las funcionalidades que Maltego ofrece, ciertamente hay muchas más por descubrir, aprender y utilizar. Espero que este texto sea útil y sirva para comenzar a explorar esta poderosa herramienta.
Basic Scanning (Shodan.io & Nmap)
En esta práctica veremos como usar Shodan para localizar servers con puertos 22 y 23 abiertos y usaremos nmap para obtener información básica de los objetivos.
CEH: "En el escaneo, por lo general, encontramos puertos abiertos, cerrados y filtrados. Cada uno son servicios totalmente diferentes, excepto unos puertos utilizados en cuanto a la presentación de un sitio web (80 o 8080). Una de las mayores vulnerabilidades es encontrar puertos de sencillo acceso, tanto el puerto 22 (SSH) como el puerto 23 (Telnet)."
En esta mini-práctica veremos como usar Shodan para localizar servers que tengan determinados puertos abiertos. Para el caso de este ejemplo estamos interesados en encontrar los puertos 22 y 23 abiertos. Luego usaremos nmap para confirmar que dichos servidores en efecto tienen ambos puertos abiertos.
Wikipedia:Telnet (Teletype Network) es el nombre de un que nos permite acceder a otra máquina para . También es el nombre del que implementa el . Su mayor problema es de seguridad, ya que todos los nombres de usuario y contraseñas necesarias para entrar en las máquinas viajan por la como (cadenas de texto sin ). Esto facilita que cualquiera que espíe el tráfico de la red pueda obtener los nombres de usuario y contraseñas. Por esta razón dejó de usarse, ante la llegada de SSH.
Wikipedia:SSH (o Secure SHell) es el nombre de un y del que lo implementa cuya principal función es el a un servidor por medio de un canal seguro en el que toda la información está cifrada. SSH permite copiar datos de forma segura (tanto archivos sueltos como simular sesiones cifradas), gestionar para no escribir contraseñas al conectar a los dispositivos y pasar los datos de cualquier otra aplicación por un canal seguro mediante SSH y también puede redirigir el tráfico del () para poder ejecutar programas gráficos remotamente.
Localizando servers con puerto 22, 23 abiertos.
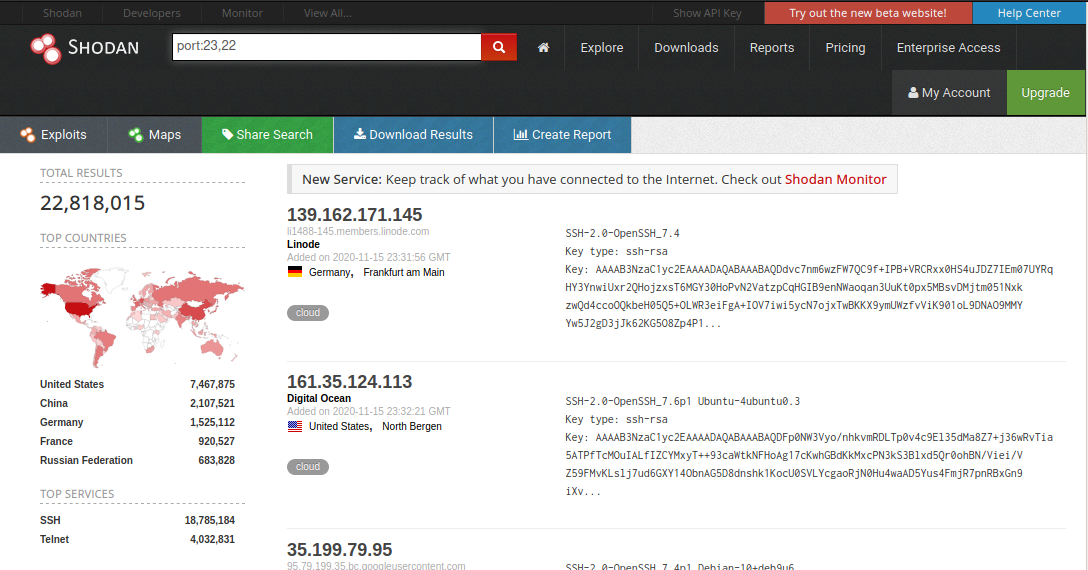
Shodan nos permite realizar búsquedas tanto desde su sitio web como desde la terminal utilizando una llave de acceso a la API. En este caso usaremos rápidamente la versión web, utilizando la búsqueda. La cual refinaremos con el uso de filtros, en este caso el filtro por puertos llamado port:.
Este filtro lo podemos utilizar de la siguiente manera:
En la barra de búsqueda ingresamos el texto port: seguido del número de puerto que por el que queremos filtrar. Por ejemplo: port:80.
Está búsqueda con shodan la realizaremos para encontrar los objetivos para esta práctica, basta con seleccionar de la lista de resultados ofrecidos por shodan las direcciones IP. Esas direcciones IP las usaremos a continuación para confirmar que los puertos abiertos para cada objetivo reportados por shodan están en efecto abiertos. Para esa confirmación usaremos la herramienta nmap.
Escaneando objetivos con nmap
Para el scanning voy a utilizar nmap como herramienta, la misma viene preinstalada en distribuciones como .
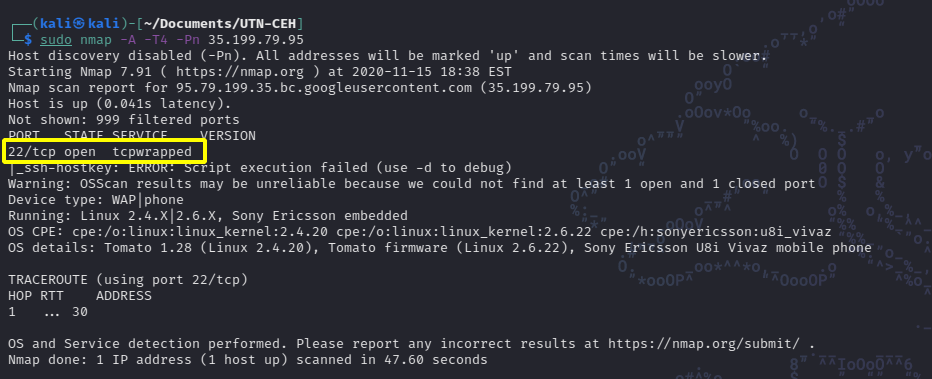
Puerto 22
Como primer ejemplo usare el objetivo 35.199.79.95 al escanearlo con nmap vemos que dicho server tiene el puerto 22 abierto. Para esto usaremos nmap con una serie de switches o flags que nos permiten refinar el tipo de scan, velocidad y puerto.
En esta mini-práctica no vamos a ahondar en nmap. Para conocer más sobre esta herramienta y como realizar distintos tipos de escaneos, sigue este 👉 .
Una vez completado el scan vemos que obtenemos confirmación de que el objetivo cuenta con el puerto 22abierto como había sido reportado por la búsqueda que realizamos en shodan. Si observamos con atención el resultado del scan, vemos que nmap nos devuelve bastante información adicional.
Puerto 23
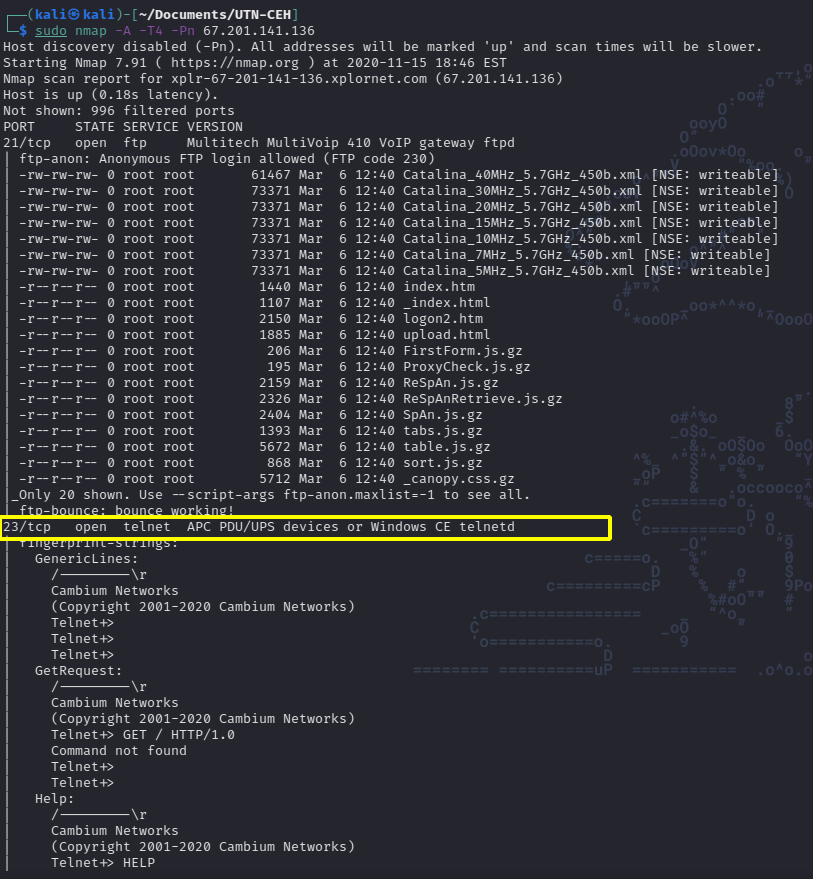
Busquemos ahora algún objetivo que tenga el puerto 23 abierto, para lo cual refinamos nuestra búsqueda en shodan con el filtro port:23, alternativamente podemos buscar directamente por el nombre del servicio, telnet.
Para encontrar servidores con el servicio de telnet activo, basta con ingresar el nombre del servicio en la barra de búsqueda. Esto funciona con otros servicios como por ejemplo SSH.
Una vez elegido el objetivo procedemos a escanearlo con nmap para confirmar que en efecto el puerto 23 esta abierto. En mi caso elegí 67.201.141.136 como objetivo:
Como vemos en los resultados el scan confirman que el puerto 23 se encuentra abierto. En este caso en particular también el puerto 21 se encuentra abierto. De esta manera vimos como ubicar servidores con determinados puertos abiertos y como usando nmap podemos comprobar que en efecto se encuentran abiertos.
Password Files & Authentication
En esta práctica veremos como están formados los archivos passwd y shadow en Linux y SAM en Windows y como se maneja la autenticación en estos SO.
imagen por pipedrive.com
Entendiendo los archivos passwd y shadow
Objetivo de la Practica del curso de CEH de la UTN:
Dentro de los entornos de los distintos SO, encontraremos archivos que tienen una gran importancia respecto a la autenticación, son el archivo passwd y el shadow, de las distribuciones de LINUX o el archivo SAM de Windows. El ejercicio de aquí es analizar y detallar esos archivos y describirlos lo mejor posible.
Anteriormente en Linux las credenciales de usuario solían ser almacenadas directamente en el archivopasswd. No obstante por limitaciones y cuestiones de seguridad actualmente solo almacena información de las cuentas de usuarios, mientras que los hashes de los passwords se almacenan en el archivo shadow.
El archivo se encuentra comúnmente en la siguiente ubicación /etc/passwd y su contenido es de texto plano. Generalmente el acceso de solo lectura es permitido dado que muchas utilidades utilizan su contenido para relacionar IDs a las correspondientes cuentas de usuario. Dentro del mismo podemos encontrar una lista de system accounts. De cada cuenta se exponen las siguientes piezas de información: Username , Password, UID, GID, UserID Info, Home Dir, Command/Shell. Veamos que significa cada uno y como es la estructura general de este archivo y sus datos.
Estructura del archivo /etc/passwd
Ya mencionamos que el archivo passwd almacena información en texto plano. Dicha información es almacenada de a una entrada por línea. Cada línea delimita sus campos usando los dos puntos :.
Veamos un diagrama de la estructura de cada línea.
Veamos una descripción sobre que función cumple cada una de las partes:
Username: Comúnmente usado para el proceso de login, de longitud entre 1 y 32 caracteres.
Password: Un carácter x que indica que el password hash esta almacenado en el archivo /etc/shadow.
Permisos: Este archivo suele ser de solo lectura para los usuarios y propiedad de root.
Leyendo el Archivo /etc/passwd
Veamos que contenido obtenemos al ejecutar el comando en alguna de nuestras máquinas virtuales.
cat /etc/passwd
vemos que los resultados incluyen una larga lista de cuentas de administración, servicios y finalmente usuarios.
Entendiendo el archivo /etc/shadow
Ya mencionamos que actualmente las credenciales en Linux residen en gran parte en el archivo /etc/passwd pero también mencionamos que el password hash de cada usuario se almacena en el archivo llamado /etc/shadow. Veamos en detalle como es la estructura de este otro archivo.
De igual forma que en el archivo /etc/passwd la data dentro de /etc/shadow se almacena también línea por línea. Incluso cada una de las líneas de este archivo se corresponde 1 a 1 con las del archivo password.
Incluso existen herramientas como unshadow (parte de JohnTheRipper) que nos permite recombinar los archivospasswd y shadow Para luego crackearlos rápidamente con John.
Username: El Nombre del usuario.
Password Encriptado: El password encriptado, usualmente sigue un patrón de este estilo $tipo$Sal$Hash.
Donde el tipo
Hasta acá vimos como esta compuestos los archivos /etc/passwd y /etc/shadow y como se organiza y encripta la información dentro de ellos.
Entendiendo SAM (Security Account Manager)
En Windows las contraseñas son almacenadas en el archivo SAM. Este archivo es en realidad una base de datos, donde Windows almacena las contraseñas en formato de hashes. Para generar estos hashes Windows ha utilizado distintos mecanismos a lo largo de las versiones. En particular nos centraremos en las siguientes: LM, NT-Hash(NTLM, NTLMv1 y NTLMv2).
LM Hash (LanMan Hash)
LM Hash es la forma antigua en la que Windows almacenaba las contraseñas y se remonta a los años '80. Las principal desventaja de este hash es que trabajaba con un set de caracteres limitados (14 caracteres), lo cual lo convertía en uno muy fácil de crackear. Internamente los hashes se generan mediante un mecanismo muy débil en general y la longitud del set de caracteres no es su única desventaja.
Wikipedia:Data Encryption Standard (DES) es un algoritmo de cifrado, es decir, un método para información. DES fue sometido a un intenso análisis académico y motivó el concepto moderno del y su . Hoy en día, DES se considera inseguro para muchas aplicaciones. Esto se debe principalmente a que el tamaño de clave de 56 bits es corto; las claves de DES se han roto en menos de 24 horas. . Se cree que el algoritmo es seguro en la práctica en su variante de , aunque existan ataques teóricos. Desde hace algunos años, el algoritmo ha sido sustituido por el nuevo (Advanced Encryption Standard).
Veamos rápidamente como opera el algoritmo LM:
Conversión: Se convierten todas las letras minúsculas de la contraseña a letras mayúsculas.
Modificación: Se agregan al password caracteres nulos (NULL) hasta completar los 14 caracteres.
División: Se separa el password en dos bloques, cada uno de 7 caracteres.
Considerando la facilidad con la que se puede crackear, LM Hash fue desactivado por defecto con la salida de Windows Vista y Windows Server 2008. No obstante aún se mantiene una retro compatibilidad para sistemas legacy y puede ser activado manualmente mediante una Group Policy (GPO).
Podemos ver este hash en acción usando una herramienta como la que se encuentra online en .
Como podemos observar los Hashes generados para cada contraseña en formato LM resultan iguales luego de la conversión, esto se debe al primer paso que lleva adelante el algoritmo, la conversión de minúsculas a mayúsculas. Si observamos los hashes resultantes en formato NTLM, vemos que son diferentes para cada contraseña.
Veamos que tan sencillo es crackear ese hash usando una herramienta como hashcat.
hashcat -m 3000 -a 3 hash
Dentro de la VM demoró 10min aproximadamente en crackear el password:
Como vemos es relativamente simple y rápido el proceso de crackeo de los hashes LM.
NT Hash (NTLM, NTLMv1, NTLMv2)
Actualmente en Windows se utiliza un mecanismo de hash conocido como NT Hash o NTLM Hash. Existen varias versiones de este hash que han ido mejorando la seguridad del mismo. Veamos rápidamente las características principales de cada versión.
NTLM Protocol
El protocolo NTLM es un sistema del tipo Challenge-Response el cual utiliza el intercambio de 3 mensajes para autenticar al cliente y un cuarto mensaje opcional para la integridad del intercambio. El hash tiene una longitud de 128 bits y funciona tanto para cuentas locales como para cuentas de dominio de Active Directory.
NT Hash - NTLMv1
El algoritmo para este protocolo es bastante simple para la generación del hash, y hace uso de ambos tipos de hash: LM Hash y NT Hash. Esta versión 1 de NTLM ya esta deprecada siendo actualmente mantenida para retro compatibilidad con sistemas viejos.
El algoritmo para esta versión de NTLM es bastante simple de comprender a alto nivel:
Conversión: Se convierte la contraseña a Unicode (UTF-16-LE).
Modificación: Para cada carácter agrega un 0 (Zero byte)
Hashing: Finalmente aplica el algoritmo MD4 al resultado del proceso anterior.
El algoritmo en concreto se puede consultar en Wikipedia, pero para referencia se ve así:
Wikipedia: El algoritmo en concreto se ve de la siguiente forma.
Veamos como podemos crackear este nuevo hash usando hashcat y un hash de ejemplo.
Hash de ejemplo (De la página de hashes de hashcat):
Esta vez le tomó a hashcat unos 5 minutos aproximadamente para crackear el hash.
Como podemos notar el proceso de crackeo de la versión NTLMv1 es también relativamente simple y rápido.
NT Hash - NTLMv2
La versión 2 de NTLM continúa usando el protocolo NTLM de formato challenge-response que vimos antes, pero incorpora mejoras de seguridad y criptografía para hacerlo más seguro y reemplazar a NTLMv1. También se incorpora el uso de HMAC-MD5 como algoritmo de Hashing y se incorpora el nombre de dominio como variable para el proceso de autenticación.
Negociación: Se genera el challenge de 8 bytes y es emitido por el server.
Respuesta: Se generan 2 bloques de 16 bytes con hashes HMAC-MD5 a modo de respuesta al challenge. Estos bloques de respuesta incluyen también un challenge generado en el lado del cliente, el password hash (HVAC-MD5) y puede incluirse otra información de identificación.
El hash resultante se puede apreciar en el siguiente ejemplo obtenido en la página de hashes de hashcat:
El algoritmo se puede ver en detalle en el artículo de Wikipedia, el cual proporciona información adicional.
Wikipedia: El algoritmo en concreto se ve de la siguiente forma.
Extrayendo hashes de SAM con Mimikatz
Hasta aquí vimos los diferentes tipos de manejos de passwords en Windows. Para no terminar la práctica sin aprender alguna herramienta que nos permita interactuar con estos hashes almacenados en SAM, veamos como podemos extraer estos hashes de un host Windows usando mimikatz y posteriormente crackearlos usando hashcat. No obstante no ahondaremos en detalle en como utilizar mimikatz en sí, sino que lo utilizaremos rápidamente para hacer un dump de los hashes. Quizás cubra el uso de mimikatz en otro escrito a futuro, dado que es una herramienta sumamente interesante.
Descarga mimikatz desde su repositorio:
Deberás desactivar Windows Defender, dado que mimikatz es detectado como archivo malicioso.
El primer paso es obtener una copia del archivo SAM, para lo cual usaremos la terminal de Powershell (como Admin) y copiaremos los archivos SAM y SYSTEM a nuestra carpeta de trabajo.
Deberíamos tener algo similar a esto luego de realizar ese proceso:
Ahora necesitamos abrir una consola, idealmente como administrador, y navegar hasta la carpeta donde tenemos nuestro export y mimikatz.
Lo siguiente es ejecutar mimikatz desde la terminal de Windows (PowerShell):
Ahora debemos indicarle a mimikatz que queremos extraer los hashes de archivo SAM y para ello debemos hacer uso del siguiente comando:
Como vemos mimikatz extrae los hashes presentes en la base de datos de SAM:
Por último usaremos nuevamente a nuestro amigo fiel hashcat para tratar de crackear el password de la cuenta administrador. Como podemos ver el hash esta en formato NTLM.
hashcat -m 1000 -a 3 hash
Hashcat demora nuevamente unos minutos en crackear el hash.
Fin de la práctica
Hasta aquí hemos visto como funciona el manejo de passwords tanto en Linux como en Windows y como podemos crackear distintos tipos de hashes usando mimikatz y hashcat. Cabe mencionar que también existe otro protocolo de autenticación que no hemos visto en esta práctica llamado Kerberos que es comúnmente usado para autenticación contra dominios como Active Directory.
Kerberos no forma parte del alcance de esta práctica y lo veremos en detalle más adelante.
Ha sido una práctica extensa y que me ha permitido estudiar bastante sobre los temas cubiertos, principalmente sobre el funcionamiento de autenticación en Windows que no lo tenía muy presente.
Estas prácticas están sujetas a modificaciones y correcciones, la versión más actualizada disponible se encuentra online en .
Esteganografía (Steganography)
En esta práctica veremos en que consiste la Esteganografía y realizaremos un ejercicio al respecto utilizando Steghide en Kali Linux.
En esta mini práctica veremos como podemos ocultar información dentro de otros archivos y veremos como es el proceso de extracción de esta información oculta. Con el uso de esteganografía, podemos ocultar información dentro de otro archivo que luego pueda ser distribuido sin importar que sea visto por terceros. Su contenido oculto es visible únicamente a quienes estén al tanto de que existe y sepan como extraerlo. Generalmente este contenido oculto es también encriptado de manera que se requiera una palabra clave para poder extraerlo.
Wikipedia: La esteganografía (del στεγανος steganos, "cubierto" u "oculto", y γραφος graphos, "escritura") trata el estudio y aplicación de técnicas que permiten ocultar mensajes u objetos, dentro de otros, llamados portadores, de modo que no se perciba su existencia. Es decir, procura ocultar mensajes dentro de otros objetos y de esta forma establecer un de comunicación, de modo que el propio acto de la comunicación pase inadvertido para observadores que tienen acceso a ese canal.
Leer más en el siguiente👉.
Existen diversas herramientas que nos permiten ver este proceso en acción, en esta práctica en particular usaremos Steghide.
Esteganografía básica con Steghide
La ilustración de arriba puede parecer una imagen común, sin embargo contiene oculto en su interior el poema completo llamado El Cuervo de Edgar Allan Poe. A simple vista la imagen no presenta indicios de ser algo más de lo que se puede apreciar, y con eso podemos darnos una idea del potencial de la esteganografía para ocultar información y trasladarla incluso ante la vista de terceros sin que el mensaje oculto pueda ser detectado a simple vista.
Ocultando información con Steghide
Veamos los comandos básicos de steghide que debemos usar para lograr replicar ese resultado y llevar a cabo nuestra práctica básica en esteganografía. Lo primero que debemos hacer es contar con los archivos básicos:
el uso básico de steghide es súper sencillo, basta con hacer uso de las siguientes opciones:
steghide embed -cf {cover_file} -ef {embed_image}
embed: le indica a steghide el modo que queremos usar. En este caso embed inserta contenido dentro del archivo destino.
-cf FILE: Indica a steghide el archivo que funcionara como cover, en este caso la imagen que contendrá la información oculta. Para nuestro ejemplo este archivo es RAVEN.jpg.
Como podemos ver el tamaño del archivo RAVEN.jpg sufre un cambio de peso luego del proceso. Es importante tener esto presente dado que si el mensaje que intentamos ocultar es demasiado grande, debemos recurrir a una imagen más grande que contenga la suficiente capacidad para poder almacenar nuestro mensaje. Esto ocurre así por la forma en la que la esteganografía hace uso de los bits menos significativos de la imagen para reemplazarlos por los bits que conforman nuestro mensaje oculto.
Podemos ver esto ejemplificado en la siguiente imagen donde los bits menos significativos de la imagen son alterados para almacenar los bits que conforman la palabra cat.
Viendo Información embebida con Steghide
Veamos ahora de que manera podemos usar steghide para ver si nuestra imagen contiene información oculta embebida. Para esto hacemos uso de las siguientes opciones:
steghide info {Archivo_Cover}
info FILE: el modo de operación que le indica a steghide que deseamos ver información del archivo. Entre los resultados devueltos se puede obtener: Algoritmo de encriptado usado, tamaño de archivo, nombre del archivo embebido y formato del archivo cover usado.
Como podemos ver para realizar esta operación necesitamos de la passphrase (clave) que haya sido utilizada al momento de ocultar la información. En este caso conocemos la clave, en muchos casos esta información es desconocida y deberemos recurrir a la ingeniería social, o al brute-forcing con herramientas como stegcrack para obtener la clave y poder usar este comando. Lo mismo aplica también para el proceso de extraer la información embebida.
Extrayendo información embebida con Steghide
Llegado el momento necesitaremos extraer la información oculta de la imagen, para esto usaremos las siguientes opciones de steghide:
steghide extract -sf {ARCHIVO_COVER}
extract: Indica a steghide que queremos realizar la extracción de data embebida de un archivo cover.
-sf FILE: Le indica a steghide la imagen cover desde donde queremos extraer la información embebida.
Si revisamos el contenido del archivo extraído, podemos ver que en efecto contiene el poema que habíamos ocultado antes:
De esta forma vimos como podemos hacer uso de la esteganografía para ocultar información dentro de otros archivos, que en apariencia se presentan normales para cualquiera que los vea.
Cabe aclarar que la esteganografía no se limita a archivos de imagen y texto y también se puede por ejemplo embeber Código fuente dentro audio y video con el uso de otras herramientas. En el caso de Steghide en particular nos permite ocultar información dentro de archivos con los siguientes formatos: WAV, JPEG, AU y BMP.
Steghide cuenta con numerosas opciones para refinar a gusto como se lleva a cabo el proceso de embeber contenido dentro de otros archivos. No esta dentro del alcance de esta práctica ver todo el funcionamiento de steghide y es importante tener en claro que existen distintas herramientas alternativas con las que podemos obtener el mismo resultado.
Estas prácticas están sujetas a modificaciones y correcciones, la versión más actualizada disponible se encuentra online en .
JWT Token Pirate Map
Escaneando Vulnerabilidades con Nessus
En esta práctica veremos como hacer scanning the vulnerabilidades usando Nessus Vulnerability Scanner.
Nessus
Wikipedia: 👉 .
Nessus es un programa de escaneo de vulnerabilidades en diversos sistemas operativos. Consiste en un demonio o diablo(daemon), nessusd, que realiza el escaneo en el sistema objetivo, y nessus, el cliente (basado en consola o gráfico) que muestra el avance e informa sobre el estado de los escaneos.
Instalando Nessus (Essentials)
Para poder instalar Nessus debemos crearnos una cuenta sin costo que nos dará acceso a Nessus Essentials, una versión limitada pero aún muy poderosa de Nessus que incluye suficientes escaneos para poder realizar esta práctica.
Web para registrarnos en el siguiente👉nk.
La creación de la cuenta es un proceso trivial como en cualquier web y no lo cubriremos como parte de la práctica.
Una vez estamos registrados y tenemos nuestra cuenta de Nessus Essentials recibiremos por mail nuestra clave de activación para poder descargar e instalar Nessus.
Nessus es un software que consume su buena cuota de recursos, de ser posible es recomendable tener una VM dedicada para su uso. De esta manera podemos dejar el scanning corriendo en la VM de Nessus y continuar cualquier otra tarea en nuestra VM regular de trabajo sin que afecte su fluidez y sin correr el riesgo de que otras tareas afecten los procesos de scanning de Nessus.
La página de descarga de Nessus ofrece diversas versiones según nuestro sistema operativo. Para esta práctica usaremos una VM con Kali Linux 2020.4.
Página de descarga de Nessus: 👉 .
En este caso descargaré la versión indicada para distribuciones basadas en Debian 64 bits.
La web nos pide aceptar la Licencia y comienza la descarga. Veamos como instalamos el paquete .deb descargado usando el comando dpkg -i {NombreDelArchivo.deb}.
En nuestra terminal nos dirigimos a la carpeta de descargas (o el directorio donde hayas descargado Nessus) y ejecutamos el comando:
Una vez instalado necesitamos inicializar el servicio que ejecutará el daemon llamado nessusd. Para iniciar el servicio usamos el comando /bin/systemctl start nessusd.service.
Es necesario ejecutar el comando con privilegios usando sudo.
Con esto ya tenemos Nessus listo para ser iniciado, no obstante el primer inicio involucra configuraciones adicionales antes de poder usar Nessus.
Iniciando Nessus
Para Iniciar Nessus, abrimos la siguiente URL como menciona el mensaje que recibimos luego de instalar Nessus.
Al hacerlo, recibiremos una advertencia sobre el certificado inválido. Hacemos click en el botón advanced y en el link del final Procced to kali (unsafe). Deberíamos ahora ver esta pantalla:
Con la opción Nessus Essentials seleccionada hacemos click en Continue. En el siguiente paso nos pedirá registrarnos, dado que ya tenemos nuestra cuenta y clave de activación, hacemos click en skip. En el siguiente paso ingresaremos nuestro código de activación y daremos click en continue.
Nessus nos pedirá crear una cuenta de administrador para usar la herramienta, ingresamos el user y password que deseemos y hacemos click en Submit.
A continuación Nessus comenzara a descargar e inicializar sus plugins.
Si en este punto recibes un error de que la descarga de plugins falló, visita esta 👉 al final de este escrito llamada . En caso contrario sigue leyendo.
Si todo ha salido bien, veremos la siguiente pantalla donde nos pedirá que ingresemos el usuario y contraseña que especificamos antes para la cuenta administrador.
Una vez iniciada la sesión en nessus, veremos la siguiente pantalla y tendremos todo listo para comenzar nuestra práctica.
Nuestro primer scan con Nessus (Discovery & Vulnerability Scans)
Ahora que tenemos Nessus instalado y listo, veremos a continuación como podemos realizar un scan de vulnerabilidades, que información obtenemos del mismo y como nessus presenta los resultados.
Para está práctica voy usar como objetivo las VMs de mi y veremos las vulnerabilidades que logra detectar Nessus.
Objetivos a escanear:
Ingresamos las direcciones IP en el campo targets de la ventana de bienvenida a Nessus y hacemos click en el botón submit.
Al darle submit Nessus comenzara a realizar un proceso de host discovery para ubicar hosts adicionales que puedan existir dentro de los targets especificados. Al completarse, seleccionamos los que en efecto vayamos a escanear.
Tengamos presente que Nessus Essentials nos limita en la cantidad de hosts que podemos escanear. Actualmente ese limite es de16 hosts.
En este punto basta con dar click en Run Scan y Nessus automáticamente realizará un escaneo básico de cada objetivo para comenzar a conocer un poco más sobre ellos.
Para ver nuestro scan en marcha podemos ir a la tab llamada History:
Luego de un momento veremos que las tabs llamadas Hosts y Vulnerabilities comenzarán a registrar resultados:
Dejaremos correr el scan hasta que se complete del todo, sin embargo es bueno saber que podemos ir revisando en tiempo real las detecciones registradas en las correspondientes tabs de la pantalla My Basic Network Scan.
Luego de unos minutos obtenemos el resultado del scan básico:
Como podemos ver Nessus clasifica las vulnerabilidades encontradas en base a distintos niveles de severidad y su puntaje CVSS (Common Vulnerability Scoring System) especificado por la National Vunlerability Database en su versión CVSSv2 (anteriormente estaba más alineado a CVSSv1).
Para conocer más sobre como se clasifican las severidades en CVSSv2 y sus respectivos valores, visita el siguiente 👉
Veamos en este caso en detalle la vulnerabilidad de severidad Medium detectada: SBM Signing not required.
Para ver el detalle de cualquier resultado, basta con hacerle click y Nessus nos mostrará la siguiente pantalla con todo el detalle disponible:
De cada vulnerabilidad obtendremos un detalle similar, en este caso la siguiente información es provista:
Detalle de la Vulnerabilidad:
Severidad de la vulnerabilidad: MEDIUM.
Descripción:
No es parte de esta práctica el proceso de como solucionar la vulnerabilidad, nos centraremos únicamente en el escaneo de las mismas y como son reportadas por Nessus.
El laboratorio tiene varias vulnerabilidades y no es la intención remediarlas, dado que la idea es usarlo para practicar los distintos vectores de ataque. Sin embargo si te interesa leer como solucionar esta vulnerabilidad en particular, te recomiendo el siguiente post en español del blog de 0xsecure en el siguiente 👉 .
Hasta acá vimos como podemos realizar un scan básico en una instalación limpia de Nessus y como ver el detalle de las vulnerabilidades detectadas. No obstante no es la única forma de hacer escaneos dado que normalmente luego del primer scan realizado, Nessus no vuelve a mostrar la pantalla de Bienvenida para iniciar un scan automático rápido como vimos en este ejemplo. Por este motivo en la siguiente sección veremos como podemos iniciar un scan a demanda en Nessus Essentials y los pasos necesarios para hacerlo.
Realizando Scans On Demand con Nessus (Zerologon Vuln Detection)
Una vez tenemos al menos un escaneo realizado en Nessus, al abrir el programa veremos que ya no aparece la pantalla de bienvenida para dejarnos ingresar los targets y realizar un scan básico automático. Para iniciar un nuevo escaneo debemos hacer click en el botón New Scan.
Luego de hacer click en New Scan Nessus nos muestra la siguiente pantalla donde aparecen listados los tipos de escaneos disponibles, incluyendo algunos a los cuales no vamos a tener acceso con Nessus Essentials.
Los primeros dos escaneos que aparecen listados (Host Discovery y Basic Network Scan) son los que fueron ejecutados por Nessus cuando cargamos nuestros objetivos en la pantalla de bienvenida. Entre los escaneos disponibles se encuentra uno para detectar si nuestro objetivo es vulnerable a Zerologon, una vulnerabilidad que sigue impactado a equipos que no cuentan con los parches necesarios. Veamos si alguna de nuestras VMs del lab es vulnerable, incluso en caso de no ser vulnerables veremos como es el proceso para iniciar un escaneo manualmente en Nessus (proceso que aplica a cualquier scan con mayor o menor configuraciones requeridas según el tipo de escaneo).
Para Iniciar un scan primero debemos configurarlo, comenzamos por hacer click en el scan llamado Zerologon Remote Scan y veremos la siguiente pantalla.
En esta pantalla debemos indicar un Nombre para el scan, Objetivos a escanear. Nessus es una herramienta ENORME y no es posible cubrir en esta práctica todas las posibles configuraciones para este o cualquier otro scan. Pero es importante saber que nos ofrece opciones para configurar el scan a nuestro gusto y necesidad. Entre estas opciones adicionales se encuentran ajustes como configuraciones de Ping y tipos de Ping a realizar, rango de puertos, enumeradores de puertos a usar e incluso opciones avanzadas como detener las operaciones si el host deja de responder durante el scan.
Una parte importante que debemos comprender sobre Nessus, es que todas sus funcionalidades son provistas por plugins y familias de plugins. Estos plugins son usados en los diferentes escaneos y aportan pruebas específicas que Nessus llevará a cabo. Podemos ver la lista de plugins que se usarán durante un scan en la tab llamada Plugins. En Este caso podemos ver que el scan actual solamente hace uso de un plugin para testear Zerologon.
Si hacemos click sobre el nombre del plugin (columna Plugin Name) podemos ver un detalle o resumen sobre el plugin y la vulnerabilidad que testea.
El detalle es similar al que vimos durante el primer scan e incluye todo el detalle disponible sobre la vulnerabilidad. Una vez que estemos listos con los ajustes para nuestro scan, Indicamos el nombre para el mismo y los IP objetivos:
En este punto podemos guardar nuestro scan para ejecutarlo en otro momento o bien haciendo click en el botón de la flecha abajo que tiene el botón llamado Save, podemos elegir ejecutarlo ahora mismo haciendo click en Launch:
Los scans guardados aparecerán listados en debajo de My Scans junto con los otros escaneos que hayamos realizado o guardado anteriormente.
Si no guardaste el scan podes ejecutarlo haciendo click en el botón de play que se muestra para este scan en la lista de escaneos (My Scans) como se muestra en la siguiente imagen.
De acá en adelante ocurre lo mismo que vimos durante el primer escaneo básico, Nessus realizara los testeos necesarios usando el Plugin configurado para el scan y nos devolverá los resultados de las vulnerabilidades encontradas en caso de estar presentes en los objetivos escaneados. Veamos que resultados nos ofrece:
Como podemos observar el Nessus determinó en 5 minutos que el Controlador de Dominio (DC) de nuestro lab es vulnerable al ataque Zerologon. Si hacemos click en la vulnerabilidad podemos darnos una idea de la potencia de Nessus.
Con tan solo 23 intentos pudo comprometer la seguridad del DCy verificar que en efecto es vulnerable al exploit Zerologon. Incluso vemos el detalle de la request y response enviadas por Nessus.
Hasta acá llegamos con esta práctica de scanning de vulnerabilidades con Nessus. Vimos como Instalar Nessus y realizar su configuración inicial, hasta su uso básico para realizar un scan inicial automático (Discovery y Network Basic Scan). Finalmente realizamos un scan manual a demanda para comprobar si nuestro laboratorio era vulnerable al exploit Zerologon que afecta a los Controladores de Dominio. Con dicho scan comprobamos que en efecto nuestro DC es vulnerable.
Adjunto a está práctica el reporte generado por Nessus para el scan de ZeroLogon.
Nessus cuenta con muchas opciones que no podemos llegar a cubrir en esta práctica, no obstante es bueno conocer que dispone de herramientas para crear nuestras propios templates de Policies para determinar las acciones que se llevan a cabo en cada tipo de scan. También incluye funcionalidades para generación de reportes, y reglas(rules) customizadas para el funcionamiento de los plugins. Todo esto sin tener en cuenta las demás funcionalidades y scans que se habilitan con la versión paga.
Troubleshooting Nessus
Si durante el proceso de instalación y primer inicio recibís un error de descarga o algún otro error que impide que Nessus termine de configurarse, podes probar las siguientes soluciones que pueden puede serte útiles para remediar el problema.
En mi caso, fue necesaria la solución numero dos para solucionarlo, los problemas que tuve al instalar Nessus.
Solución Número 1:
Si durante la configuración inicial de Nessus recibís el error Download Failed (Descarga Fallida) Intenta con la siguiente solución.
NOTA: Encaso de recibir un error de que la descarga a fallado. Podemos ejecutar el siguiente comando para solucionarlo sudo /opt/nessus/sbin/nessuscli update.
Una vez que ejecutamos ese comando, veremos el siguiente resultado en consola.
En algunos casos con esto ya podremos retomar la configuración de Nessus.
Solución Número 2:
En caso de que el error persista luego de intentar la solución 1 o recibamos algún error diferente que igualmente impide la correcta inicialización de Nessus. Podemos probar los siguientes comandos que resetearan por completo Nessus:
Si el error persiste: Podemos usar los siguientes comandos en orden para resetear Nessus por completo. Más información en el siguiente 👉 .
# service nessusd stop
Espero que te sea de ayuda.
Estas prácticas están sujetas a modificaciones y correcciones, la versión más actualizada disponible se encuentra online en .
Sniffing con Wireshark
En esta práctica veremos el uso básico de Wireshark para el análisis de paquetes de red.
Uso Básico de Wireshark
Wireshark es un analizador de protocolos de red más utilizado del mundo. Permite ver lo que está sucediendo en la red en detalle y es el estándar en muchas empresas comerciales y sin fines de lucro, agencias gubernamentales e instituciones educativas. Wireshark es la continuación de un proyecto iniciado por Gerald Combs en 1998 llamado Ethereal.
Al abrir Wireshark nos aparecerá una pantalla similar a la siguiente, veremos a continuación los controles más importantes que usaremos de aquí en adelante.
NTFS Stream Manipulation
En esta práctica veremos en que consiste el ataque llamado NTFS Stream Manipulation.
NTFS (New Technology File System)
NTFS es un sistema de archivos propietario de Microsoft y fue introducido como reemplazo de sistemas de archivos anteriores como FAT (File Allocation Table) y HPFS (High Performance File System) e incorpora mejoras técnicas con respecto a estos. Entre algunas de las ventajas NTFS incorpora un soporte mejorado para metadatos, mejoras en la administración de espacio en disco, mejoras de performance, un mejorado sistema de seguridad y un sistema de encriptado de archivos llamado EFS (Encrypting File System).
┌──(kali㉿kali)-[~]
└─$ sudo nmap -sC -sV -Pn -p- -T5 -O -v -oN results 192.168.31.131
[sudo] password for kali:
Host discovery disabled (-Pn). All addresses will be marked 'up' and scan times will be slower.
Starting Nmap 7.91 ( https://nmap.org ) at 2020-12-06 13:48 EST
NSE: Loaded 153 scripts for scanning.
NSE: Script Pre-scanning.
Initiating NSE at 13:48
Completed NSE at 13:48, 0.00s elapsed
Initiating NSE at 13:48
Completed NSE at 13:48, 0.00s elapsed
Initiating NSE at 13:48
Completed NSE at 13:48, 0.00s elapsed
Initiating ARP Ping Scan at 13:48
Scanning 192.168.31.131 [1 port]
Completed ARP Ping Scan at 13:48, 0.05s elapsed (1 total hosts)
Initiating Parallel DNS resolution of 1 host. at 13:48
Completed Parallel DNS resolution of 1 host. at 13:48, 0.01s elapsed
Initiating SYN Stealth Scan at 13:48
Scanning 192.168.31.131 [65535 ports]
Discovered open port 53/tcp on 192.168.31.131
Discovered open port 135/tcp on 192.168.31.131
Discovered open port 139/tcp on 192.168.31.131
Discovered open port 445/tcp on 192.168.31.131
Discovered open port 49703/tcp on 192.168.31.131
Discovered open port 9389/tcp on 192.168.31.131
Discovered open port 49667/tcp on 192.168.31.131
Discovered open port 3268/tcp on 192.168.31.131
Discovered open port 636/tcp on 192.168.31.131
Discovered open port 49674/tcp on 192.168.31.131
Discovered open port 49676/tcp on 192.168.31.131
Discovered open port 3269/tcp on 192.168.31.131
Discovered open port 49666/tcp on 192.168.31.131
SYN Stealth Scan Timing: About 45.08% done; ETC: 13:49 (0:00:38 remaining)
Discovered open port 593/tcp on 192.168.31.131
Discovered open port 5985/tcp on 192.168.31.131
Discovered open port 49673/tcp on 192.168.31.131
Discovered open port 88/tcp on 192.168.31.131
Discovered open port 464/tcp on 192.168.31.131
Discovered open port 49710/tcp on 192.168.31.131
Discovered open port 49686/tcp on 192.168.31.131
Discovered open port 389/tcp on 192.168.31.131
Completed SYN Stealth Scan at 13:49, 55.14s elapsed (65535 total ports)
Initiating Service scan at 13:49
Scanning 21 services on 192.168.31.131
Completed Service scan at 13:50, 53.60s elapsed (21 services on 1 host)
Initiating OS detection (try #1) against 192.168.31.131
Retrying OS detection (try #2) against 192.168.31.131
NSE: Script scanning 192.168.31.131.
Initiating NSE at 13:50
Completed NSE at 13:51, 40.06s elapsed
Initiating NSE at 13:51
Completed NSE at 13:51, 0.07s elapsed
Initiating NSE at 13:51
Completed NSE at 13:51, 0.00s elapsed
Nmap scan report for 192.168.31.131
Host is up (0.00045s latency).
Not shown: 65514 filtered ports
PORT STATE SERVICE VERSION
53/tcp open domain Simple DNS Plus
88/tcp open kerberos-sec Microsoft Windows Kerberos (server time: 2020-12-06 18:49:48Z)
135/tcp open msrpc Microsoft Windows RPC
139/tcp open netbios-ssn Microsoft Windows netbios-ssn
389/tcp open ldap Microsoft Windows Active Directory LDAP (Domain: CHUKARO.local0., Site: Default-First-Site-Name)
| ssl-cert: Subject: commonName=Chukaro-DC.CHUKARO.local
| Subject Alternative Name: othername:<unsupported>, DNS:Chukaro-DC.CHUKARO.local
| Issuer: commonName=CHUKARO-CHUKARO-DC-CA
| Public Key type: rsa
| Public Key bits: 2048
| Signature Algorithm: sha256WithRSAEncryption
| Not valid before: 2020-11-24T20:30:01
| Not valid after: 2021-11-24T20:30:01
| MD5: b134 42d1 5e7e 2394 dc8a 0eae 3e6f bb9f
|_SHA-1: 0fb3 428c 8b1f 8a6b b92a 785a a84e cc3f c393 74dd
|_ssl-date: 2020-12-06T18:51:20+00:00; 0s from scanner time.
445/tcp open microsoft-ds?
464/tcp open kpasswd5?
593/tcp open ncacn_http Microsoft Windows RPC over HTTP 1.0
636/tcp open ssl/ldap Microsoft Windows Active Directory LDAP (Domain: CHUKARO.local0., Site: Default-First-Site-Name)
| ssl-cert: Subject: commonName=Chukaro-DC.CHUKARO.local
| Subject Alternative Name: othername:<unsupported>, DNS:Chukaro-DC.CHUKARO.local
| Issuer: commonName=CHUKARO-CHUKARO-DC-CA
| Public Key type: rsa
| Public Key bits: 2048
| Signature Algorithm: sha256WithRSAEncryption
| Not valid before: 2020-11-24T20:30:01
| Not valid after: 2021-11-24T20:30:01
| MD5: b134 42d1 5e7e 2394 dc8a 0eae 3e6f bb9f
|_SHA-1: 0fb3 428c 8b1f 8a6b b92a 785a a84e cc3f c393 74dd
|_ssl-date: 2020-12-06T18:51:20+00:00; 0s from scanner time.
3268/tcp open ldap Microsoft Windows Active Directory LDAP (Domain: CHUKARO.local0., Site: Default-First-Site-Name)
| ssl-cert: Subject: commonName=Chukaro-DC.CHUKARO.local
| Subject Alternative Name: othername:<unsupported>, DNS:Chukaro-DC.CHUKARO.local
| Issuer: commonName=CHUKARO-CHUKARO-DC-CA
| Public Key type: rsa
| Public Key bits: 2048
| Signature Algorithm: sha256WithRSAEncryption
| Not valid before: 2020-11-24T20:30:01
| Not valid after: 2021-11-24T20:30:01
| MD5: b134 42d1 5e7e 2394 dc8a 0eae 3e6f bb9f
|_SHA-1: 0fb3 428c 8b1f 8a6b b92a 785a a84e cc3f c393 74dd
|_ssl-date: 2020-12-06T18:51:20+00:00; 0s from scanner time.
3269/tcp open ssl/ldap Microsoft Windows Active Directory LDAP (Domain: CHUKARO.local0., Site: Default-First-Site-Name)
| ssl-cert: Subject: commonName=Chukaro-DC.CHUKARO.local
| Subject Alternative Name: othername:<unsupported>, DNS:Chukaro-DC.CHUKARO.local
| Issuer: commonName=CHUKARO-CHUKARO-DC-CA
| Public Key type: rsa
| Public Key bits: 2048
| Signature Algorithm: sha256WithRSAEncryption
| Not valid before: 2020-11-24T20:30:01
| Not valid after: 2021-11-24T20:30:01
| MD5: b134 42d1 5e7e 2394 dc8a 0eae 3e6f bb9f
|_SHA-1: 0fb3 428c 8b1f 8a6b b92a 785a a84e cc3f c393 74dd
|_ssl-date: 2020-12-06T18:51:20+00:00; 0s from scanner time.
5985/tcp open http Microsoft HTTPAPI httpd 2.0 (SSDP/UPnP)
|_http-server-header: Microsoft-HTTPAPI/2.0
|_http-title: Not Found
9389/tcp open mc-nmf .NET Message Framing
49666/tcp open msrpc Microsoft Windows RPC
49667/tcp open msrpc Microsoft Windows RPC
49673/tcp open ncacn_http Microsoft Windows RPC over HTTP 1.0
49674/tcp open msrpc Microsoft Windows RPC
49676/tcp open msrpc Microsoft Windows RPC
49686/tcp open msrpc Microsoft Windows RPC
49703/tcp open msrpc Microsoft Windows RPC
49710/tcp open msrpc Microsoft Windows RPC
MAC Address: 00:0C:29:1C:F8:3D (VMware)
Warning: OSScan results may be unreliable because we could not find at least 1 open and 1 closed port
OS fingerprint not ideal because: Timing level 5 (Insane) used
No OS matches for host
Network Distance: 1 hop
TCP Sequence Prediction: Difficulty=263 (Good luck!)
IP ID Sequence Generation: Incremental
Service Info: Host: CHUKARO-DC; OS: Windows; CPE: cpe:/o:microsoft:windows
Host script results:
| nbstat: NetBIOS name: CHUKARO-DC, NetBIOS user: <unknown>, NetBIOS MAC: 00:0c:29:1c:f8:3d (VMware)
| Names:
| CHUKARO-DC<20> Flags: <unique><active>
| CHUKARO-DC<00> Flags: <unique><active>
| CHUKARO<00> Flags: <group><active>
| CHUKARO<1c> Flags: <group><active>
|_ CHUKARO<1b> Flags: <unique><active>
| smb2-security-mode:
| 2.02:
|_ Message signing enabled and required
| smb2-time:
| date: 2020-12-06T18:50:40
|_ start_date: N/A
NSE: Script Post-scanning.
Initiating NSE at 13:51
Completed NSE at 13:51, 0.00s elapsed
Initiating NSE at 13:51
Completed NSE at 13:51, 0.00s elapsed
Initiating NSE at 13:51
Completed NSE at 13:51, 0.00s elapsed
Read data files from: /usr/bin/../share/nmap
OS and Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 153.56 seconds
Raw packets sent: 131159 (5.775MB) | Rcvd: 75 (3.856KB)
Opción 2: Editar el dominio usando el panel de propiedades de la entidad (este panel es genérico a cualquier entidad que tengamos seleccionada):
UID (User ID):
A cada user se le asigna un
ID
, siendo
0
reservado para el
root
, los de
1 a 99
reservados para cuentas predefinidas, los de
100 a 999
reservados para cuentas administrativas y de sistema. Finalmente los IDs superiores a
1000
son asignados para los usuarios.
GID (Group ID): El grupo primario al que pertenece el user, almacenado en /etc/groups.
UserID Info: Permite almacenar información adicional del usuario, como ser el nombre del servicio (service accounts) o detalles del tipo Nombre completo del user.
User Home Directory: La ruta absoluta la carpeta home del user en cuestión.
Comando o Shell: Indica el shell o comando. Comúnmente es un shell pero no es siempre el caso.
es el algoritmo de hash que fue usado para encriptar el password.
$6$: Indica el uso de SHA-512.
$5$: Indica el uso de SHA-256.
$2a$: Indica el uso de Blowfish.
$1$: Indica el uso de MD5 Hash.
$2y$: Indica el uso de Eksblowfish.
La Sal (salt en ingles): es un valor que se utiliza para garantizar la aleatoriedad del hashing, de manera que el hash resultante siempre sea distinto.
Finalmente el Hash value: El resultado de hash generado para el encriptado de nuestro password.
Ultimo cambio de password: Representa una fecha en días, contando desde el primero de enero de 1970 hasta el día de hoy.
Edad mínima del password: Normalmente se setea en cero indicando que el no hay un mínimo establecido para la caducidad del password. Si contiene otro valor, el mismo representa la cantidad de días que deben transcurrir para cambiar el password.
Edad máxima del password: Número de días antes de que el password expire.
Período de Advertencia: La cantidad de días antes de que el password expire. Por ejemplo un valor de 6 le recordará al usuario cambiar el password 6 días antes de que el password caduque.
Período de Inactividad: El número de días luego de que el password haya vencido donde la cuenta de usuario quedará desactivada. Normalmente esta en cero.
Fecha de expiración: La fecha donde la cuenta de usuario fue efectivamente deshabilitada.
Sin Uso (Reservados para futuro uso): Actualmente es ignorado, se guarda para futuros posibles usos.
Generación de KEYs: Se generan 2 claves DES para cada bloque.
Cifrado: Se cifra cada bloque con DES y un texto fijo con el valor KGS!@#$%.
Hash Generado: El hash se genera en base a la concatenación de ambos bloques encriptados con DES.
Respuesta Corta (shorter-response): En este bloque de respuesta se incluyen los 8 bytes del challenge del lado de cliente y los 16 bytes de del bloque. Esto genera un bloque de respuesta de 24 bytes consistente con el formato usado en NTLMv1.
Segunda Respuesta: El segundo bloque de respuesta usa un challenge de longitud variable, que incluye entre otras cosas: el horario actual en formato NT Time, un valor aleatorio de 8 bytes, el nombre de dominio e información estándar adicional. Considerando que esta respuesta debe incluir el challenge del lado del cliente, su longitud variara en cada caso.
Imagen por Guang Ying Yuan, Advisory IT specialist at IBM.
-ef FILE: Indica la ruta al archivo que se ocultará en el archivo cover. Para nuestro ejemplo este archivo es MESSAGE que contiene el poema completo El Cuervo.
passphrase: la clave necesaria para extraer el contenido oculto. Para este ejemplo la clave es POE.
passphrase
: La clave para poder extraer el contenido oculto.
esgeeks.com: Este diagrama muestra dos imágenes de 4 píxeles tanto en color como en valores binarios. Cada bloque de binario representa el valor del píxel correspondiente.
Obtenemos una descripción del posible impacto de la vulnerabilidad. En este caso nos indica que la
firma de comunicaciones con el servidor
SMB
,
no es requerida
. Lo cual puede permitir a un eventual atacante llevar a cabo ataques del tipo
MIM (Man in the Middle)
.
Solución: Parte del detalle ofrecido por Nessus para cada vulnerabilidad incluye posibles soluciones para mitigar el riesgo de cada vulnerabilidad detectada. En este caso la solución es activar el requisito de que toda comunicación deba estar firmada (Digitally Sign Communications).
Artículos relacionados: Como parte del informe de detalle Nessus también suele incluir links a diversos artículos donde se explica la tecnología afectada (por ejemplo SMB) y recursos adicionales que puede incluir otros artículos donde se vea en detalle la vulnerabilidad.
Listado de Puertos y Hosts Afectados: Incluye el detalle de los puertos afectados y la lista de hosts donde se detectó la misma vulnerabilidad (esta cantidad se corresponde al valor indicado en la columna Count en la lista de vulnerabilidades de la pantalla anterior). En este caso vemos que solo dos de los tres equipos del lab están afectados por esta vulnerabilidad.
Detalles del plugin (Plugin Details): Información básica y de referencia sobre cual plugin fue utilizado para realizar la detección.
Información de Riesgo (Risk Information): Detalle del los factores de riesgo y los diferentes puntajes CVSS que aplican para esta vulnerabilidad.
Información de la Vulnerabilidad: Esta sección nos muestra un detalle adicional sobre la vulnerabilidad y la fecha en que fue publicada originalmente.
Ciertamente es una herramienta muy interesante y que me interesa comprender en mayor profundidad. Quizás dedique un escrito en particular profundizando en su uso en algún momento. Por ahora quizá realice alguna que otra actualización a esta misma práctica.
Filtros: Una de los controles que más usaremos en Wireshark es la barra de filtros. Mediante el uso de filtros podemos identificar los paquetes que cumplan uno o más criterios de filtrado. Veremos lo básico de filtros más adelante.
Archivos Recientes: Esta sección (Vacía por default al instalar Wireshark de cero) recopila los últimos archivos PCAP que hayamos abierto. También nos permite abrir archivos directamente haciendo click en el texto Open.
Interfaces para Captura: En esta sección podemos ver el listado de las interfaces presentes en el equipo donde se ejecuta Wireshark. Esta sección varía de equipo a equipo. Se puede seleccionar una interfaz en particular y comenzar a escuchar su trafico de red haciendo doble click sobre el nombre de la interfaz. El gráfico representa la actividad de red en cada interfaz.
Coloring Rules en Wireshark
En Wireshark los paquetes se clasifican por color según el tipo de protocolo usado y errores encontrados en estos. Para poder ver las reglas de colores para los paquetes de red, vamos a: View -> Coloring Rules.
Como podemos observar Wireshark nos presenta todas las reglas de coloreado que están actualmente configuradas.
Es importante tener presente esta configuración de colores y comenzar a familiarizarnos con ella, dado que es una forma visualmente sencilla de identificar paquetes y protocolos de forma rápida.
Usando Filtros
Existe una gran cantidad de filtros disponibles en Wireshark que nos permitirán refinar nuestras búsquedas hasta encontrar el tráfico de red específico a una dirección IP, MAC Address, Tipo de Protocolo, etc. No cubriremos todos los posibles filtros en esta sección, nos limitaremos a los necesarios para entender el funcionamiento general de los mismos y los usaremos a lo largo de esta práctica.
Los filtros en Wireshark utilizan operadores lógicos y operadores de comparación como en los lenguajes de programación. Haciendo uso de estos operadores podemos combinar nuestros filtros para realizar filtrados refinados para encontrar exactamente el tráfico de red que queremos capturar y ver.
Operadores de Comparación
Los operadores de comparación nos permiten comparar valores en nuestras expresiones de filtrado. Estos operadores son los siguientes:
Operador
Uso
eq o ==
Igual a x valor.
ne o !=
No igual (not equal) a x valor.
gt o >
Mayor que x valor.
lt o <
Menos que x valor.
ge o >=
Mayor o igual que x valor.
Operadores Lógicos
Los operadores Lógicos nos permiten comparar expresiones de filtrado. Estos operadores son los siguientes:
Operador
Uso
and o &&
Nos permite enlazar condiciones, todas deben cumplirse.
or o ||
Nos permite enlazar condiciones, al menos una debe cumplirse.
xor o ^^
Únicamente una de las condiciones debe cumplirse.
not o !
Negación, la condición no debe cumplirse.
[…]
Permite seleccionar una sub-secuencia.
Cabe destacar que en Wireshark los filtros se clasifican en dos grandes grupos, Capture Filters (Filtros de Captura) y Display Filters (Filtros de visualización). Veamos a continuación un breve detalle de cada uno.
Capture Filters
Los filtros de captura son aplicados antes de iniciar la captura de paquetes y no pueden ser alterados durante la captura. Si prestamos atención en la pantalla inicial de Wireshark, este control también se presenta como una barra de búsqueda en la sección Capture:
Este tipo de filtros nos permite por ejemplo capturar el tráfico de un rango de IP en particular, el tráfico de un tipo de protocolo en particular, el tráfico únicamente del protocolo IPV4, etc.
Cabe mencionar que estos filtros también son accesibles desde el menu de Wireshark: Capture -> Options (CTRL + K).
En esta ventana también podemos activar/desactivar el modo promiscuo de Wireshark.
Promiscuous mode: En modo activo Wireshark tratará de detallar todo paquete de red que vea en la interfaz, este o no dirigido a nuestro equipo.
Non-Promiscuous Mode: En este modo Wireshark únicamente interceptará el tráfico de red de la interfaz seleccionada si su origen o destino es dirigido a nuestro equipo.
Uso
Capture Filter
Capturar tráfico IPV4, ignorando otros protocolos como ARP,etc.
ip
Capturar tráfico por puerto, por ejemplo port 53 capturará el tráfico de DNS.
port #
Capturar el tráfico desde/ hacia el IP especificado.
host <IP>
Captura el tráfico por rango de puertos, por ejemplo tcp portrange 1200-2112.
tcp portrange
Más sobre Capture filters en la documentación oficial de Wireshark.
Click en el siguiente 👉link.
Display Filters
Los Display Filters, nos permiten realizar filtrado de datos directamente sobre la lista de resultados y son los que usaremos regularmente para ubicar el tráfico de red que nos interese inspeccionar. Wireshark utiliza este tipo de filtros para las Coloring Rules que vimos antes y es una de sus principales funcionalidades. Cabe destacar que la cantidad de filtros que se pueden utilizar es enorme y esta fuera del alcance de esta práctica verlos en detalle. Mencionaremos sin embargo, los que usaremos en esta práctica.
Según la misma 👉Wiki de Wireshark, actualmente más de 261000 campos de 3000 protocolos son soportados para su uso con filtros.
Uso
Display Filter
Filtrar por IP (Destino)
ip.dest == 192.168.1.1
Filtrar por IP (Origen)
ip.src == 192.168.1.2
Filtrar por IP
ip.addr == 192.168.1.3
Filtrar por Subnet
ip.addr = 192.168.1.1/24
Filtrar por puerto(TCP)
tcp.port == 21
Más sobre Display Filters en la documentación de Wireshark.
Click en el siguiente 👉link.
Analizando paquetes de red (FTP Sniffing)
Veamos ahora como podemos capturar las credenciales de logueo a un servicio de FTP analizando el trafico de red de una interfaz. Cabe destacar que este mismo proceso de análisis puede llevar a cabo de igual manera luego de abrir archivo PCAP/PCAPNG.
Para esta práctica voy a utilizar lo siguiente:
Interfaz: eth0
Puerto: 21
Si quieres realizar esta práctica locamente, al menos la parte del análisis. Puedes descargar el archivo PCAPNG desde el link debajo 👇
Para comenzar en la pantalla principal de Wireshark aplicaremos un filtro de captura, seleccionando únicamente la interfaz eth0. Para lo cual podemos directamente hacer doble click sobre el nombre de la interfaz:
Luego de esto Wireshark comenzará a capturar el tráfico de red de esa interfaz automáticamente. Dejamos la captura activa y nos dirigimos a la terminal para conectarnos por FTP a nuestra VM e intentamos loguearnos. Luego de esto volvemos a Wireshark y hacemos click en el botón rojo de stop para detener la captura.
Comenzamos conectándonos al servidor FTP, en este caso usé un usuario recientemente configurado para el acceso a FTP.
Para esta práctica también usare el Server de mi Lab local de Active Directory. Mas detalle en el siguiente 👉link.
Una vez detenido el proceso de captura, debemos ver algo similar a esto en Wireshark:
Ahora hagamos usos de distintos filtros que nos permitan ubicar específicamente el tráfico FTP. Por ejemplo podemos filtrar por el trafico en el puerto 21:
Y como podemos ver Wireshark aplica el Display Filter correspondiente sobre los resultados:
Alternativamente podemos directamente filtrar por el protocolo FTP simplemente escribiendo:
También nos puede interesar ver el tráfico del puerto 20 (FTP-DATA) junto con el del puerto 21 (FTP):
Filtremos directamente por ftp y hagamos click derecho en el paquete número 58 y elegimos la opción Follow -> TCP Stream.De esta manera podemos seguir el paso a paso del trafico de red generado por nuestro intento de login al la maquina virtual Windows Server.
Combinación de teclas para TCP Stream: CTRL + ALT + SHIFT + T
Al abrirse el TCP Stream, veremos la secuencia de interacción entre el usuario y el servicio FTP. Vemos que el usuario listó los archivos del directorio y descargo el mismo.
Como podemos ver las credenciales de login fueron ftpuser:Test123 y el usuario descargó el archivo Executive_Secrets.txt desde el servidor FTP a su equipo. Veamos como podemos ubicar esta acción en el tráfico de red y extraer los contenidos de ese archivo.
Primero filtremos por ftp-data:
Luego seleccionamos el paquete 386 donde se hace la transferencia del archivo (RETR), y seguimos el TCP Stream como vimos antes.
Finalmente podemos ver el contenido del archivo descargado por el usuario durante la sesión FTP. Y podemos guardarlo en nuestro equipo haciendo uso de las opciones que nos provee Wireshark.
Wireshark nos permite cambiar el formato en el que se muestra la data, lo que es útil si en lugar de una archivo de texto plano estuviéramos tratando de recuperar un ejecutable por ejemplo. En ese caso podemos ver el contenido en modo raw y guardarlo como .exe.
Hasta acá vimos como usar lo básico de Wireshark y repasamos algunos de los filtros que nos serán de utilidad a la hora de analizar tráfico de red. Wireshark dispone de muchísimas más opciones y no está en el alcance de esta práctica cubrir esta herramienta a fondo.
Estas prácticas están sujetas a modificaciones y correcciones, la versión más actualizada disponible se encuentra online en el siguiente link.
Desde Windows NT 3.1 es el sistema de archivos por default en la familia de Windows NT como por ejemplo Windows Server 2008, Windows 7 y Windows 10 por nombrar algunos.Es soportado en sistemas operativos de escritorio y servidor. El soporte en Linux y BSD es posible mediante el NTFS Driver (NTFS-3G) el cual ofrece soporte para lectura y escritura. En macOS se ofrece soporte de lectura.
NTFS Alternate Data Streams
Para poder entender como funciona el ataque de NTFS Stream Manipulation, primero debemos conocer lo básico sobre ADS (alternate data streams). ADS es una característica del sistema de archivos NTFS (NT File System) que permite que más de un stream de datos pueda estar asociado a mismo archivo. Cada archivo, tiene su contenido principal conocido como default stream y puede tener uno o más ADS.
Estos streams de datos usan un formato en particular: fileName:streamName:streamType. Por ejemplo un ADS cuyo stream es llamado payload y esta alojado dentro de un archivo llamado malicioso.txt se vería de esta forma: malicioso.txt:payload:$DATA. Cabe destacar que los ADS pueden existir en cualquier tipo de archivo, incluyendo ejecutables. El contenido de los ADS puede ser de cualquier tipo y por ende no es necesario que sea del mismo tipo del archivo que lo contenga. Por ejemplo un archivo de imagen JPG puede contener streams de datos del tipo video, audio, etc.
Otra característica de ADS es que su peso no es reportado como parte del peso total del archivo que lo contiene y tampoco aparecen listados en aplicaciones muy utilizadas en Windows como lo es Windows Explorer. Que un archivo contenga uno o más ADS tampoco altera el funcionamiento original del archivo y este seguirá funcionando como siempre. Por estos motivos, los archivos con ADS maliciosos son algo bastante común.
Cuando se copian o mueven archivos que contienen ADS a sistemas de archivos que no soportan Alternate Data Streams, el usuario recibe una advertencia de que los streams se perderán. Sin embargo, esta advertencia no suele ser emitida cuando los archivos se adjuntan por correo o son subidos a una web. En esos casos toda información de ADS que estaba contenida en el archivo se perderá.
NTFS Stream Manipulation
La idea principal detrás de la manipulación de NTFS Data Streams es la de ocultar información dentro de otro archivo, normalmente con fines maliciosos. Como por ejemplo permite a un atacante ocultar información sensible recolectada de un sistema, dentro de los mismos archivos del usuario sin que este note cambio alguno en sus archivos. El atacante luego puede simplemente extraer esos archivos aparentemente normales del sistema objetivo llevándose consigo toda la información relevante almacenada en los ADS.
Veamos el uso básico de ADS usando la consola de comandos de Windows
En esta parte de la práctica veremos como podemos crear un archivo de texto y posteriormente agregarle Alternate Data Streams con información únicamente visible para NTFS.
Para comenzar abrimos la consola de Windows (cmd) y creamos nuestro primer archivo, en este caso un archivo de texto. Para lo cual usamos el comando echo , el contenido de nuestro archivo y finalmente el redireccionamos todo a nuestro archivo usando el carácter > seguido por el nombre de archivo y extensión que queremos crear. Veamos esto en la consola:
echo{contenido}>{nombre de archivo}.{extensión}
Como podemos observar en la imagen, el archivo es creado correctamente y tiene un peso de 36 bytes. Podemos usar el comando type para ver el contenido del mismo:
Ahora, usando nuevamente el comando echo como hicimos en el paso 1, agregaremos el primer Alternate Data Stream a nuestro archivo. La única diferencia es que en este caso debemos indicar el nombre del stream. Veamos esto en la consola:
Como podemos observar el stream parece haberse agregado sin error y nuestro archivo reporta el mismo tamaño de 36 bytes. También vemos que en ningún lado es reportado que existe un ADS en el archivo. Esto es precisamente lo que convierte a los ADS en una buena opción para esconder información sin que el usuario lo note.
Agreguemos un segundo ADS y veamos de que manera podemos obtener información de los mismos en la consola:
Para ver el contenido de data streams adicionales que pueda contener un archivo, hacemos uso del comando dir /r el cual lista los archivos incluyendo sus ADS. Como podemos ver en la imagen anterior el tamaño reportado del archivo sigue siendo el mismo 36 bytes a pesar de que contiene dos ADS de 23 bytes cada uno. Si prestamos atención al espacio en disco disponible luego de crear el archivo y luego de cada creación de los ADS, podemos observar que NTFS si lleva el registro correcto de cuanto espacio esta siendo utilizado en realidad.
Si abrimos el archivo con el bloc de notas vemos que únicamente se presentan los datos del default stream:
Si queremos editar o ver el contenido de cada ADS, debemos invocarlo directamente de la siguiente forma:
Como dijimos antes el contenido del ADS puede ser de cualquier formato al igual que el archivo que los contenga. Cabe destacar que Alternate Data Streams se pueden agregar a directorios de la misma forma que conarchivos. Veamos esto rápidamente en la consola:
Como podemos observar en la imagen la carpeta DIRECTORIO contiene un ADS llamado ADS1.
ADS con PowerShell
PowerShell incorpora ciertos comandos (cmdlets) que facilitan trabajar con ADS. Veamos como podemos listar los ADS presentes en el archivo que hemos creado en esta práctica:
En el caso de PowerShell, el default stream se conoce como unnamed stream, o stream sin nombre ya que aparece listado simplemente como :$DATA.
Para ver el contenido por ejemplo del ADS2, podemos hacer uso del comando Get-Content de la siguiente manera:
Si queremos agregar contenido al ADS podemos hacerlo con el comando Set-Content. Veamos como podemos agregar dentro de un nuevo archivo de texto un ADS llamado payload que contenga un archivo ejecutable como por ejemplo el clásico Microsoft Paint. Para eso hacemos uso del siguiente comando:
También podemos hacer uso del cmdletAdd-Content.
En este comando explícitamente indicamos el encoding para los bytes, el readcount en 0 (para leer el archivo en una sola operación y el comando Get-Command para obtener rápidamente la ruta de mspaint.exe sin tener que especificarla manualmente. Luego simplemente indicamos el nombre del stream que queremos agregar usando el switch -stream {nombreDelStream}.
Como podemos ver en la imagen, nuestro archivo de texto contiene un nuevo ADS. Veamos como podemos ejecutar ese ADS que sabemos contiene un archivo ejecutable. Para lograr esto podemos usar Windows Management Instrumentation para crear un proceso que ejecute nuestro ADS.
Este método de ejecución de archivos usando wmic parece haber sido reparado en Windows en la versión que tengo en las VMs por ende al intentar ejecutarlo tanto en CMD como en Powershell obtengo un error y el programa no se ejecuta. En versiones vulnerables de Windows, el programa sería ejecutado directamente y veríamos en nuestro caso a mspaint.exe en ejecución. Voy a investigar un poco más sobre otras formas de ejecutar ADS en versiones actualizadas de Windows, de encontrar alguna actualizaré este artículo.
Actualización: Luego de varios intentos logré agregar el contenido de la calculadora de Windows calc.exe a nuestro archivo de práctica y ejecutarlo correctamente usando wmic:
Como vemos al ejecutarse el comando correctamente genera un nuevo proceso el cual retorna un ProcessId = 4344 y un ReturnValue = 0 indicando que el proceso se completó exitosamente. No comprendo porque no funcionó el intento inicial, quizás sea el ejecutable de mspaint.exe o algún error que estoy cometiendo y no logro darme cuenta. Si te das cuenta del problema, házmelo saber con un tweet a mi cuenta @tzero86.
Si queremos borrar un ADS en particular podemos hacer uso del cmdletRemove-Item de la siguiente manera. Por ejemplo para eliminar nuestro ADS llamado payload:
Como podemos ver nuestro archivo ahora contiene solo dos ADS adicionales. Hasta aquí vimos y practicamos un poco NTFS Stream Manipulation.
Estas prácticas están sujetas a modificaciones y correcciones, la versión más actualizada disponible se encuentra online en el siguiente link.